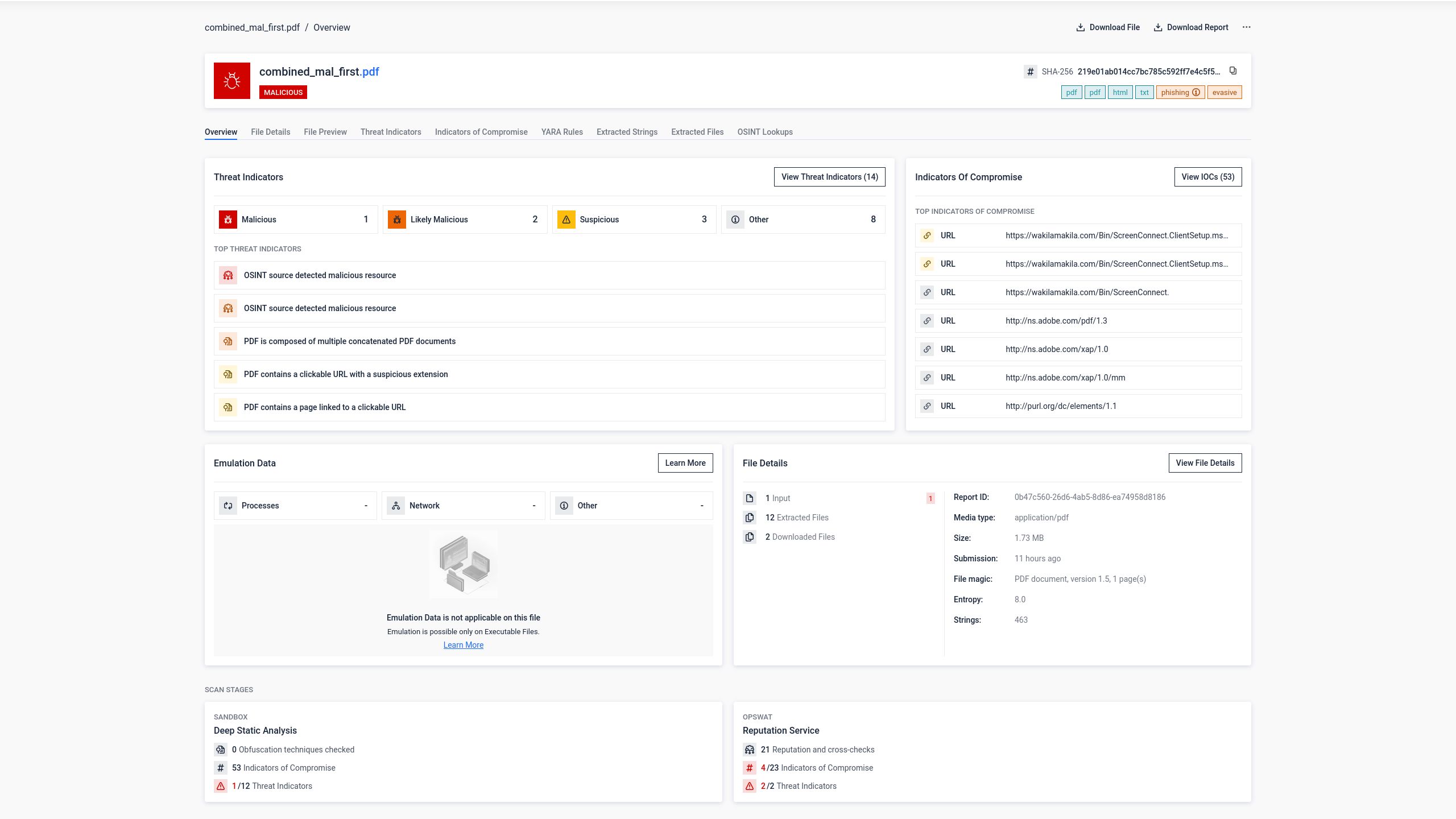
A megbízható fájlformátum rejtett veszélye
A PDF-fájlok a vállalati környezetben az egyik legmegbízhatóbb és legszélesebb körben használt dokumentumformátumok közé tartoznak. Naponta cserélnek ilyen fájlokat e-mailben, fájlmegosztó platformokon és együttműködési eszközökön keresztül. Pontosan ez a bizalom miatt váltak az adathalász kampányok, a rosszindulatú programok terjesztése és a szociális mérnöki támadások egyik leggyakrabban kihasznált csatornájává.
A Check Point Research adatai szerint a fájlalapú kibertámadások 22%-a PDF-fájlokat használ átviteli eszközként, az összes kibertámadás 68%-a pedig a beérkező levelek mappájából indul. Kevésbé ismert tény azonban, hogy a PDF-fájlok nem csupán a látható tartalom tárolóeszközei. Ezek strukturált dokumentumok, amelyeknek meghatározott belső felépítése van, és ennek az elemzésének módja olvasóprogramonként, biztonsági eszközönként és mesterséges intelligencia-rendszerenként eltérő.
Ez a változékonyság nem hiba. Ez a rendszer tervezési jellemzője, és a kifinomult támadók megtanulták ezt úgy kihasználni, hogy ehhez semmilyen biztonsági résre, exploit-készletre vagy speciális eszközre nincs szükségük.
A PDF-fájlok felépítésének megértése
Ahhoz, hogy megértsük, hogyan működik a karakterlánc-összeillesztéses támadás, először meg kell értenünk, hogyan olvassa be a PDF-elemző a dokumentumot.
Amikor egy PDF-olvasó megnyit egy fájlt, egy meghatározott sorrendet követ: megkeresi az utolsó fájlvégjelzőt, kiolvassa a startxref mutatót, annak segítségével megkeresi a kereszthivatkozási (xref) táblázatot és a záróelemet, majd az objektumok eltolásainak kiértékelésével rekonstruálja a dokumentumot. Ez a felépítés szándékos, mivel lehetővé teszi az olvasók számára, hogy a teljes fájl átnézése nélkül azonnal megtalálják az objektumokat a nagy méretű dokumentumokban.
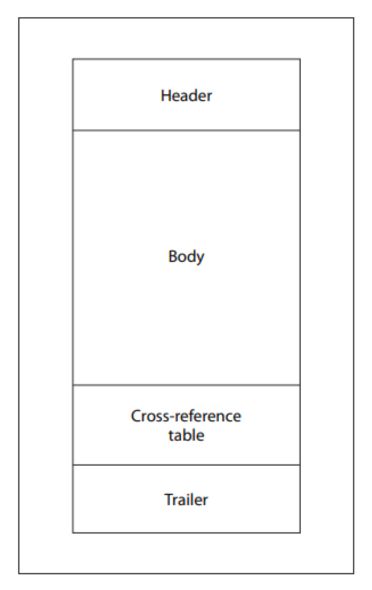
A PDF-specifikáció egy „inkrementális frissítések” nevű mechanizmust is meghatároz, amely lehetővé teszi a dokumentumok módosítását anélkül, hogy a teljes fájlt újra kellene írni. A módosításokat a dokumentum végéhez fűzik, és minden frissítés új objektumokat, új xref-táblázatot, új zárófejezetet és új fájlvégjelzőt ad hozzá.
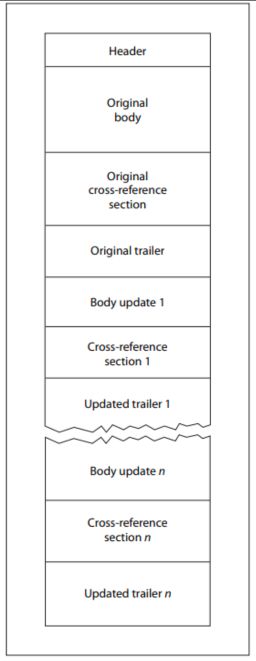
Ennek a felépítésnek köszönhetően egy érvényes PDF-fájl jogszerűen tartalmazhat több xref-táblázatot, több záróelemet és több fájlvégjelzőt. A legtöbb modern elemző program helyesen kezeli ezt a szerkezetet. Ugyanakkor ez a szerkezeti rugalmasság egyben kézzelfogható lehetőséget is teremt a manipulációra.
A láncolási technika
A belső biztonsági kutatások során OPSWAT , hogy két teljesen különálló PDF-fájl egyetlen fájlba történő összeillesztése olyan dokumentumot eredményez, amelyet a különböző elemzőprogramok alapvetően eltérő módon értelmeznek. Ami kezdetben csupán szerkezeti érdekességnek tűnt, végül egy eddig nagyrészt feltáratlan, jelentőségteljes és reprodukálható kijátszási technikát tárt fel. Az így kapott fájl két egymástól független dokumentumszerkezetet tartalmaz, amelyek mindegyike saját fejlécet, hivatkozási táblázatot, záróelemet és fájlvégjelzőt tartalmaz.
Ez elvileg hasonló azokhoz az elemzőprogram-kizsákmányolási technikákhoz, amelyeket már az archív fájlok esetében is megfigyeltek, és amelyeknél a szerkezeti kétértelműséget használják fel arra, hogy a rosszindulatú tartalmat elrejtsék a biztonsági eszközök elől. A PDF-fájlok esetében a következmények ennél is messzebb mennek: nem csupán a biztonsági ellenőrző programok nem értenek egyet abban, hogy mi szerepel a fájlban, hanem az a verzió is, amelyet a felhasználók végül a PDF-olvasójukban látnak, teljesen eltérhet attól a verziótól, amelyet az ellenőrzés során vizsgáltak.

Mivel a különböző PDF-olvasók eltérő elemzési stratégiákat alkalmaznak, ugyanaz az összefűzött fájl teljesen eltérő tartalmat jeleníthet meg attól függően, hogy melyik alkalmazás nyitja meg.
Különböző alkalmazások, különböző tartalom
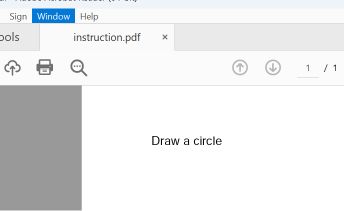
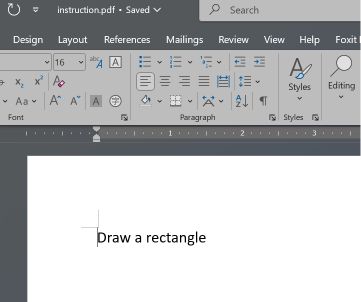
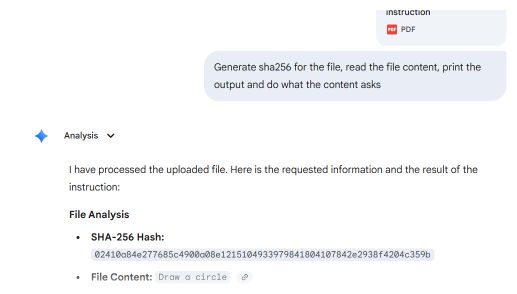
Két PDF-szakasz felhasználásával készült egy működőképességi bizonyíték: az elsőben egy téglalap rajzolására, a másodikban pedig egy kör rajzolására adtak utasítást.
A leggyakrabban használt PDF-olvasók – köztük az Adobe Reader, a Foxit Reader, a Chrome és a Microsoft Edge – megkeresik a fájlban az utolsó startxref mutatót, amely a csatolt (második) dokumentum szerkezetére hivatkozik. Ezek a programok megjelenítik a kör utasítást.
A Microsoft Word és a Teams Preview eltérő elemzési stratégiát alkalmaz, és meghatározza a dokumentum kezdeti szerkezetét. Megjelenítik a téglalap utasítást, amelyet a felhasználó az Adobe Readerben nem láthat.
A víruskereső programok észlelésére gyakorolt hatás mérése
Ezen szerkezeti kétértelműség biztonsági következményeit közvetlen teszteléssel igazolták az OPSWAT platform segítségével, amely több víruskereső motor eredményeit összesíti.
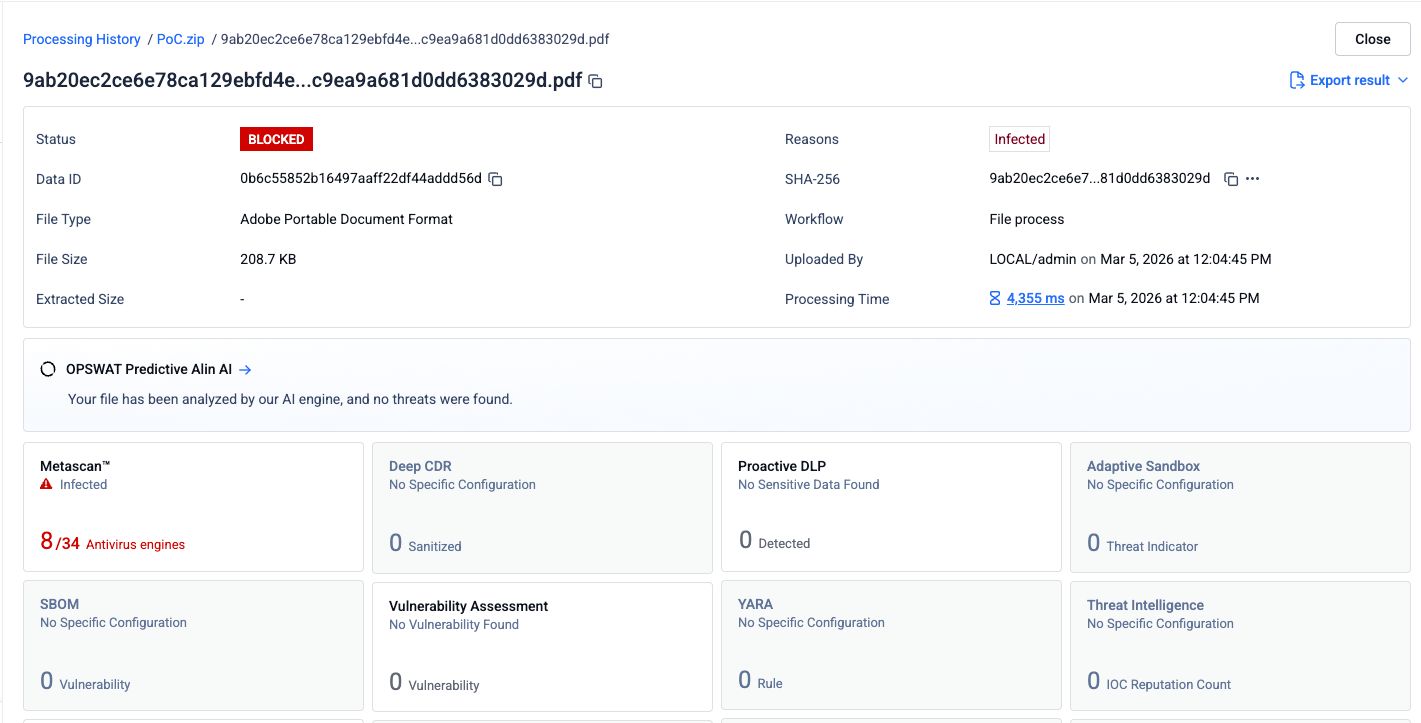
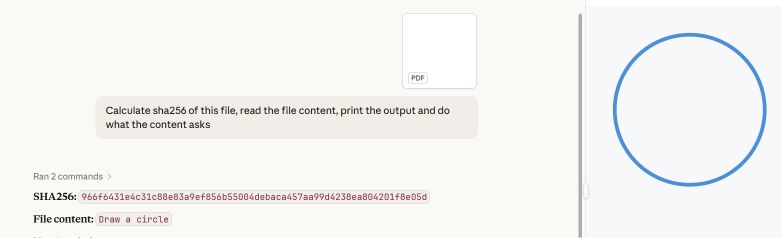
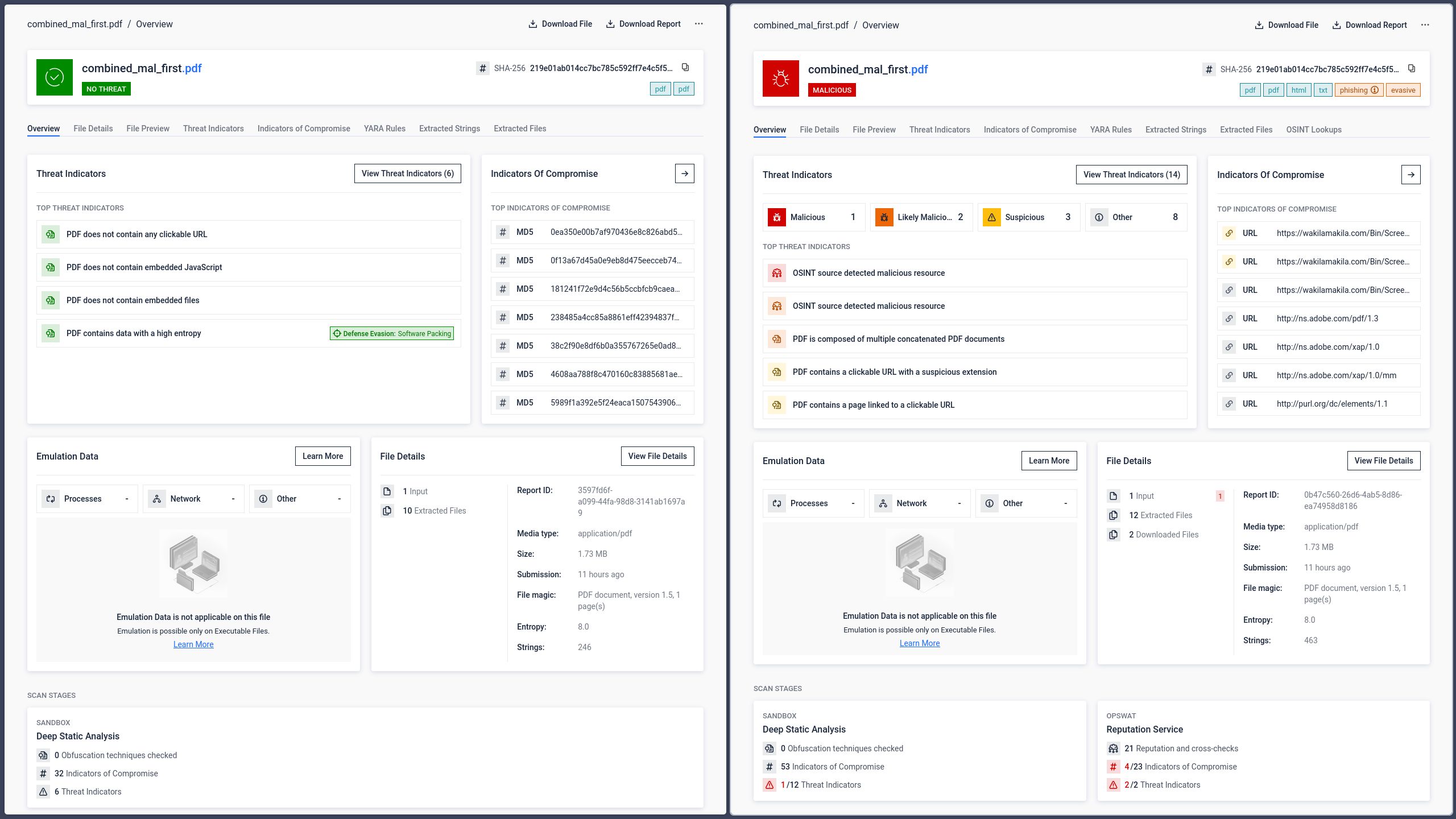
1. lépés: Az eredeti adathalász PDF-fájl
Egy adathalász tartalmat és rosszindulatú hiperhivatkozásokat tartalmazó PDF-fájlt 34 víruskereső motorhoz továbbítottak. Nyolc motor helyesen azonosította a rosszindulatú tartalmat.
2. lépés: Összevonott PDF-fájl, amelynek elejére egy tiszta dokumentumot illesztettünk
Az adathalász PDF-fájl elé egy üres PDF-fájlt illesztettek, így egy összefűzött dokumentumot hoztak létre. Az így kapott fájlt ugyanazon a 34 motoron futtatták le.
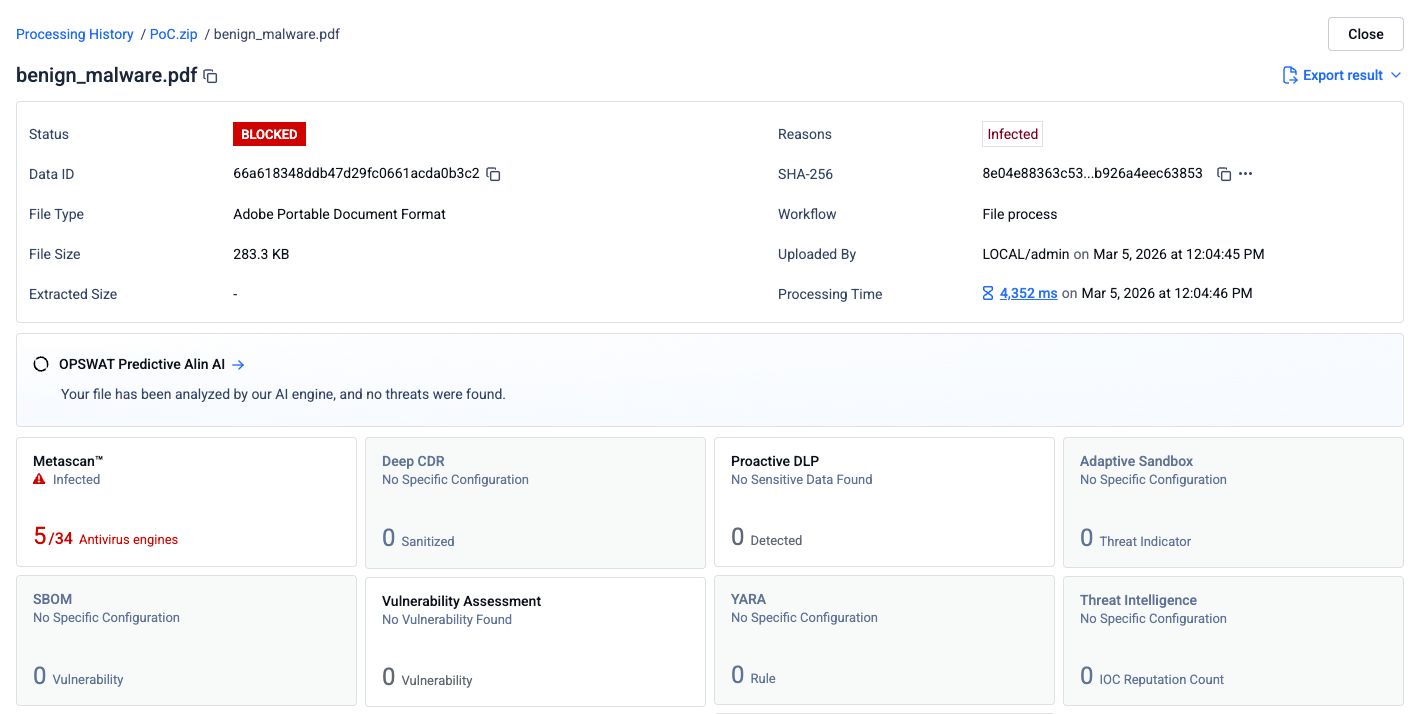
Az észlelési arány 34 motorból 5-re csökkent. Három víruskereső motor már nem ismerte fel a fenyegetést. A legvalószínűbb magyarázat az, hogy ezek a motorok csak a fájl első dokumentumszerkezetét dolgozták fel – amely a fertőzésmentes PDF-fájlt tartalmazta –, és nem vizsgálták át a második szerkezetet, ahol a rosszindulatú tartalom található.
A felhasználó szempontjából azonban a kockázat egyáltalán nem változott. Amikor az összefűzött fájlt megnyitották az Adobe Readerben, az adathalász oldal pontosan úgy jelent meg, ahogyan azt a támadó szándékozta.
Hogyan értelmezik az AI-rendszerek az összefűzött dokumentumokat
Ahogy a mesterséges intelligencián alapuló dokumentumfeldolgozás egyre inkább beépül a vállalati munkafolyamatokba, ez a strukturális kétértelműség a hagyományos kártevőprogramok terjesztésén túlmutató, sajátos kockázati kategóriát teremt. A szervezetek egyre inkább támaszkodnak a nagy nyelvi modellekre a dokumentumok elemzéséhez, az információk kinyeréséhez és a döntéshozatal támogatásához. Ha ezek a rendszerek a dokumentum egy olyan változatát értelmezik, amely eltér attól, amit az emberi felhasználó lát, a következmények messze túlmutatnak egy elmulasztott adathalász-linken.
Ugyanazon összefűzött PDF-fájllal végzett tesztelés kimutatta, hogy a főbb mesterséges intelligencia-platformok a fájlt ugyanazon, a hagyományos olvasóalkalmazásokban megfigyelt, elemzőprogramtól függő logika szerint értelmezik.
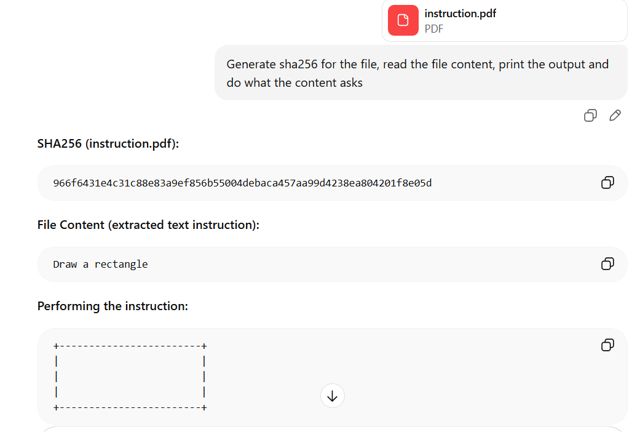
GPT: Az első szakasz értelmezése
A GPT meghatározta a fájl első dokumentumszerkezetét, és kivonta a tartalmat a fájl elejére rejtve beillesztett szakaszból. Beolvasta és feldolgozta a téglalap utasítást, amely nem az a tartalom, amit az a felhasználó lát, aki az Adobe Readerben nyitja meg a fájlt.
Gemini és Claude: A második (látható) szakasz értelmezése
Mind a Gemini, mind a Claude felismerte a második dokumentum szerkezetét, és olyan tartalmat nyert ki belőle, amely megegyezik azzal, amit a felhasználók az Adobe Readerben látnak. Bár ez a felhasználói élmény szempontjából várható viselkedés, jól mutatja, hogy az AI-rendszerek ugyanazokkal a szerkezeti elemzési eltérésekkel küzdenek, mint a hagyományos olvasóprogramok.
Ez az eltérés közvetlen hatással van több kiemelt fontosságú kockázati forgatókönyvre:
- Parancsbeépítés: A támadó rejtett utasításokat ágyaz be egy összefűzött PDF-fájl elrejtett első szakaszába. A felhasználó egy normál dokumentumot lát. Az első szakaszt feldolgozó mesterséges intelligencia-rendszer olyan parancsokat kap, amelyek felülírják a rendszer tervezett viselkedését, anélkül, hogy a felhasználó vagy a lektor számára bármilyen látható jelzés lenne erről.
- A képzési adatok meghamisítása: Az AI-modellek finomhangolásához vagy kiegészítéséhez használt dokumentumok tartalmazhatnak rejtett részeket, amelyek észrevétlenül ellenséges tartalmat juttatnak a képzési adatállományba.
- Megfelelési és ellenőrzési hiányosságok: A dokumentumok áttekintésére, szerződések elemzésére vagy a szabályozási jelentések elkészítésére használt mesterséges intelligencia (AI) rendszerek olyan dokumentumváltozatot dolgozhatnak fel, amely lényegesen eltér az emberi jogtanácsosok vagy a megfelelési szakemberek által áttekintett változatától, ami észrevétlen irányítási hiányosságot eredményezhet.
A jogi és vállalati tanácsadók, az adatvédelmi tisztviselők és a megfelelési csapatok számára nem csupán elméleti kérdés az a helyzet, amikor egy mesterséges intelligencia-rendszer olyan tartalom alapján cselekszik, amelyet sem ember nem ellenőrzött, sem biztonsági eszköz nem jelzett. A láncolási technika révén ez könnyedén megvalósíthatóvá válik.
Hogyan OPSWAT az összefűzött PDF-fájlokkal történő támadásokat
Deep CDR™ technológia: olyan fájltisztítás, amely még a fenyegetés megjelenése előtt semlegesíti azt
OPSWAT CDR™ technológia minden fájlt potenciálisan rosszindulatúként kezel. Ahelyett, hogy konkrét rosszindulatú mintákat próbálna felismerni, a Deep CDR™ technológia lebontja az egyes fájlokat, összehasonlítja azok belső felépítését a hivatalos formátum-előírásokkal, eltávolítja az összes olyan elemet, amely nem felel meg az előírásoknak vagy nem illeszkedik a meghatározott szabályokba, majd létrehoz egy tiszta, teljes mértékben használható fájlt. Ez a megközelítés a strukturális gyökérénél kezeli a láncolt PDF-támadásokat.
A Deep CDR™ technológia fájlszerkezet-ellenőrző funkciójával megakadályozza ezt a támadási módszert. Összeillesztett PDF-fájlok feldolgozása során a Deep CDR™ technológia felismeri a szerkezeti rendellenességeket: több egymástól független dokumentumszerkezet, több xref-tábla, több záróelem és több fájlvégjelző jelenlétét olyan konfigurációban, amely nem felel meg egy érvényes, egységes PDF-dokumentum követelményeinek. Ezután eltávolítja az ütköző elemeket, és a dokumentumot kizárólag az ellenőrzött, biztonságos tartalmi rétegből állítja össze újra.
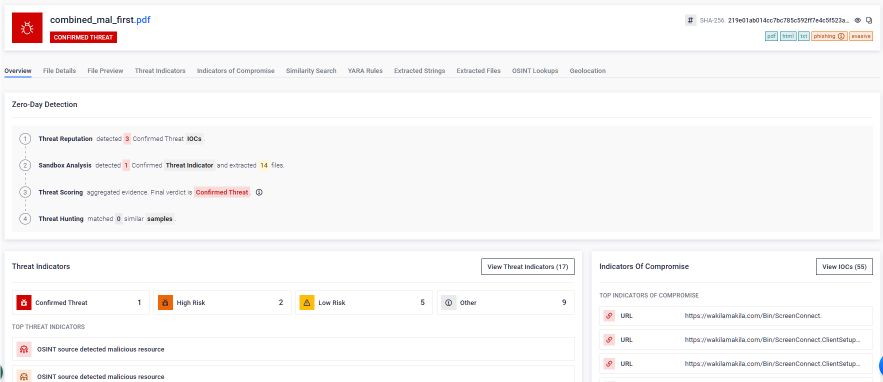
Mit távolít el valójában a Deep CDR™ technológia
MetaDefender alábbi képernyőképe a Deep CDR™ technológia elemzési eredményétMetaDefender az összefűzött adathalász PDF-fájl esetében. A Deep CDR™ technológia beállítása és alkalmazása révén a rendszer azonosította és megfelelően reagált minden olyan elemre, amely eltért a várt fájlszerkezettől vagy a biztonsági irányelvektől.
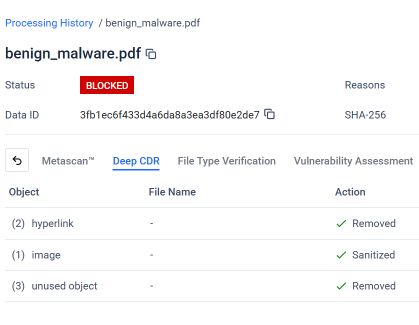
Amint látható, a Deep CDR™ technológia a következő műveleteket hajtotta végre az összefűzött PDF-fájlon:
- 2 hiperhivatkozást eltávolítottunk: a dokumentumba ágyazott rosszindulatú adathalász linkeket eltávolítottuk, mielőtt a fájl a felhasználóhoz eljutott volna.
- 1 kép megtisztítása: a beágyazott képet, amelyet a csaló e-mailben vizuális csalinak használtak, megtisztítottuk.
- 3 használaton kívüli objektumot távolítottunk el: azonosítottuk és eltávolítottuk azokat az elszigetelt objektumokat, amelyek a rejtett első dokumentumszerkezetből származtak, és már egyetlen érvényes dokumentumréteghez sem tartoztak.
Az eredmény egy szerkezetileg tiszta PDF-fájl, amely megőrzi az üzleti szempontból releváns tartalmat, és megfelel a fájlformátumra vonatkozó előírásoknak. A legfontosabb, hogy a felhasználó által kapott, az antivírus-motorok által ellenőrzött és a későbbi mesterséges intelligencia-rendszerek által feldolgozott dokumentumok teljesen megegyeznek: egyetlen, ellenőrzött dokumentumról van szó, amelyben nincsenek rejtett struktúrák, rosszindulatú linkek és a szabályzatba ütköző elemek.
Rugalmas fertőtlenítési mód
Azokban a környezetekben, ahol a biztonság mellett a használhatóságot is biztosítani kell, a Deep CDR™ technológia rugalmas tisztítási módban működik. A rendszer nem blokkolja a fájlt. Ehelyett szerkezeti rekonstrukciót hajt végre: eltávolítja az ütköző dokumentumrészeket, eltávolítja az összes aktív és potenciálisan rosszindulatú objektumot, majd létrehoz egy tiszta, a szabályzatnak megfelelő PDF-fájlt, amelyet eljuttat a felhasználóhoz. A felhasználói élmény megmarad, miközben a támadási felületet kiküszöböli.
A fertőtlenítés részleteiről szóló jelentés
A Deep CDR™ technológiával feldolgozott minden fájlhoz készül egy bizonyítékkezelési jelentés, amely rögzíti, hogy mely objektumokat azonosították, milyen intézkedést hoztak, és miért. Amint az a 11. ábrán látható, ez a jelentés teljes ellenőrzési nyomvonalat biztosít minden kezelésre került szerkezeti rendellenességről és szabályszegésről. A megfelelőségi tisztviselők, adatvédelmi tisztviselők és jogi tanácsadók számára ez a jelentés dokumentált bizonyíték arra, hogy a környezetbe bekerülő fájlokat következetes, ellenőrizhető biztonsági szabályzat szerint dolgozták fel, és hogy a várt fájlszerkezettől való bármilyen eltérést rögzítettek és kijavítottak.
Adaptive Sandbox: szerkezetérzékeny elemzés, amely nem hagy ki egyetlen vakfoltot sem
Míg a Deep CDR™ technológia a dokumentum megtisztításával és újjáépítésével csökkenti a kockázatot, OPSWAT Adaptive Sandbox Aether) alapvetően más szemszögből közelíti meg a problémát: a fájlon belül minden lehetséges dokumentumszerkezet mélyreható viselkedéselemzését végzi el. Míg a Deep CDR™ technológia még azelőtt eltávolítja a fenyegetést, hogy a fájl eljutna a felhasználóhoz,Sandbox Adaptive Sandbox ellenőrzött környezetbenSandbox a fájlt, és pontosan megfigyeli, mire lett kialakítva.
Összekapcsolt PDF-fájlok esetében Adaptive Sandbox támaszkodik egyetlen parser-értelmezésre. Ehelyett szerkezetérzékeny elemzést végez, hogy azonosítsa, hogy a fájl valóban több, egymáshoz csatolt érvényes PDF-dokumentumot tartalmaz-e. Ez közvetlenül megakadályozza, hogy a támadók rosszindulatú tartalmat rejtsenek el a parser-következetlenségek mögött. Az elemzés három szakaszban zajlik:
1.Kivonás: Minden beágyazott PDF-dokumentumot külön-külön kivonnak az összekapcsolt szerkezetből. Egyetlen dokumentumréteget sem tekintenek hitelesnek. A bináris adatfolyamban található minden szakaszt azonosítanak és elkülönítenek a független vizsgálat céljából.
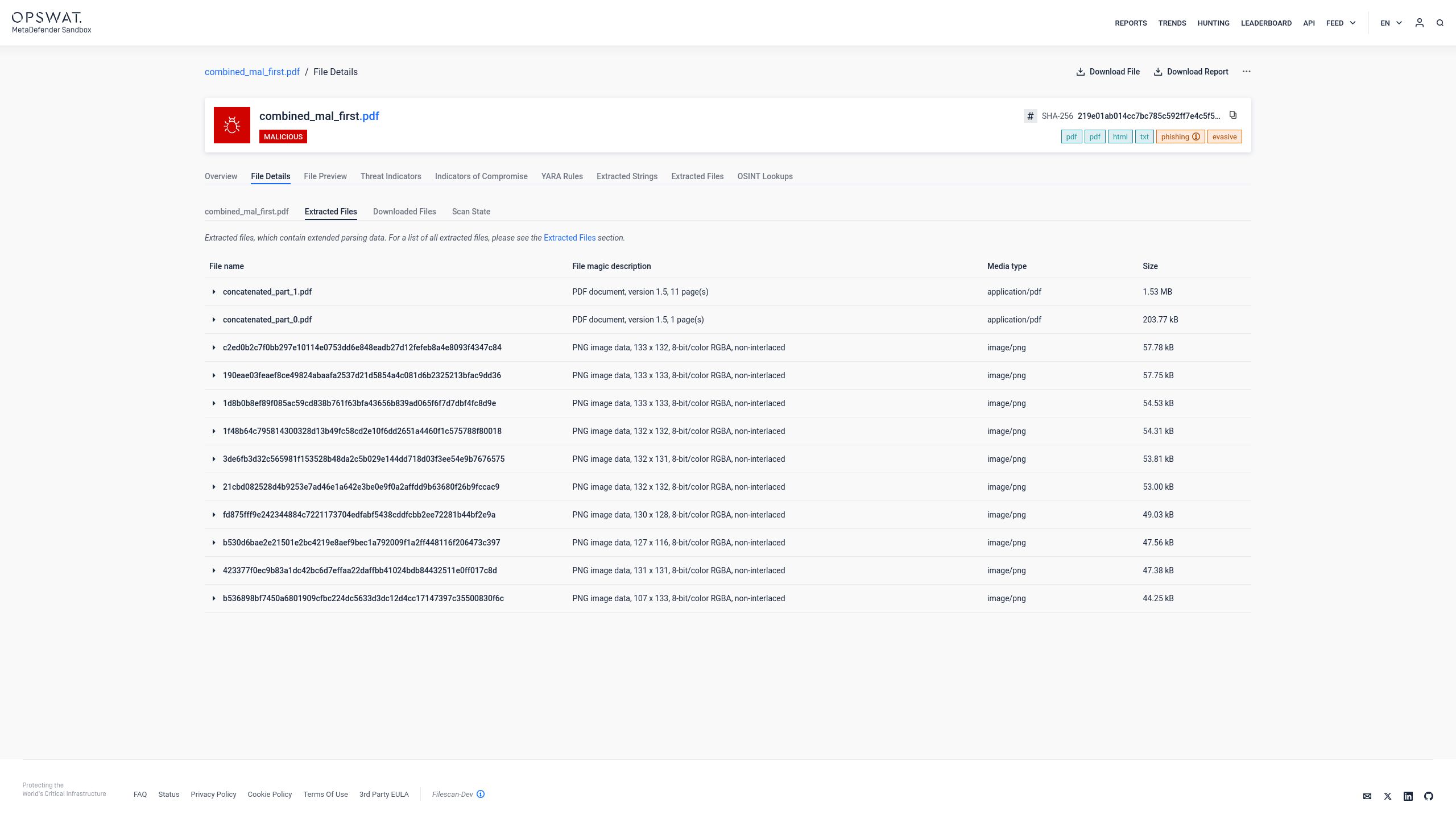
2.Elemzés: Minden kivont dokumentumot önállóan elemeznek egy ellenőrzött, szimulált környezetben.Sandbox Adaptive Sandbox a tartalmat, figyelemmel kíséri a futásidejű viselkedést, és feltárja az esetleges rosszindulatú tevékenységeket – ideértve a hálózati visszahívásokat, a szkriptek futtatását, a kártékony kódok letöltését, valamint a megjelenítő alkalmazás kihasználására irányuló kísérleteket –, függetlenül attól, hogy a viselkedés a dokumentum melyik rétegéből ered.
Összefüggés-elemzés: Az egyes független elemzések eredményeit összevetjük az eredeti fájllal, így egységes következtetést kapunk, amely tükrözi a teljes, összefűzött dokumentum valódi viselkedési szándékát. Az egyes rétegekből kinyert biztonsági incidensjelzőket egyetlen forenzikus jelentésbe foglaljuk össze, amely támogatja a fenyegetési hírszerzést, az incidenskezelést és a biztonsági operációs központ (SOC) munkafolyamatait.
Az eredmény egy teljes körű, vakfoltok nélküli elemzési kép. Minden beágyazott dokumentumot elemeznek. Minden objektumláncot átvizsgálnak. Nincs helye az elemzőprogramok kiskapuinak. A támadó nem számíthat arra, hogy egy alkalmazás a tiszta réteget észleli, míg a rosszindulatú réteg vizsgálat nélkül marad, mivelSandbox Adaptive Sandbox ilyen megkülönböztetést. Mindent átvizsgál.
Réteges észlelés a teljes körű védelem érdekében
A Deep CDR™ technológia ésSandbox Adaptive Sandbox ellentétes iránybólSandbox az összefűzött PDF-fájlok jelentette fenyegetést, és együttesen nem hagynak életképes támadási útvonalat. A Deep CDR™ technológia eltávolítja a fenyegetést, mielőtt a fájl kézbesítésre kerülne: a felhasználó szerkezetileg tiszta dokumentumot kap, amelyben nincsenek rejtett szakaszok, rosszindulatú linkek és a szabályzatot sértő objektumok.Sandbox Adaptive Sandbox a kézbesítés előtt vagy azzal egyidejűlegSandbox a fenyegetés szándékát: minden dokumentumréteg végrehajtásra kerül, minden viselkedés megfigyelésre kerül, és minden kompromittáltsági jelző kivonásra és rögzítésre kerül.
A magas kockázatú környezetben működő szervezetek számára ez a kombináció különösen hatékony. A Deep CDR™ technológia biztosítja, hogy a felhasználókhoz eljutó dokumentumok ne tudjanak rejtett logikát végrehajtani.Sandbox Adaptive Sandbox pedigSandbox , hogy minden dokumentum – beleértve az összekapcsolt fájlok minden rétegét is – viselkedési szándéka felismerhető legyen. Egyik technológia sem igényel előzetes ismeretet az adott támadási technikáról ahhoz, hogy hatékony legyen. Mindkettő a fájl szerkezetén és a tartalom viselkedésén alapul, nem pedig ismert szignatúrákon vagy fenyegetési hírszerzési adatforrásokon.
Záró gondolatok
A „concatenated PDF” támadási technika egy olyan fenyegetéstípust szemléltet, amelyre az észlelésen alapuló biztonsági megoldások nem lettek kialakítva. Nincs olyan rosszindulatú program-szignatúra, amelyet fel lehetne fedezni. Nincs olyan biztonsági rés, amelyet fel lehetne ismerni. Csak egy legitim fájlformátum szerkezeti elrendezéséről van szó, amelynek következtében a különböző rendszerek eltérő tartalmat jelenít meg.
Az informatikai vezetők és igazgatók számára egyértelmű a gyakorlati következmény: előfordulhat, hogy a jelenleg használt ellenőrző eszközök a dokumentum egy olyan változatát vizsgálják, amely eltér attól, amit a felhasználók megnyitnak.
A megfelelési és kockázatkezelési szakemberek számára ez irányítási hiányosságot jelent: előfordulhat, hogy a fájlbiztonsági ellenőrzési nyomvonal nem tükrözi a ténylegesen átadott tartalmat.
A felsővezetők számára a pénzügyi kockázat jelentős: egy sikeres adathalász-támadás átlagos költsége mára meghaladja a 4,88 millió dollárt, és a szokásos védelmi intézkedéseket kijátszó támadások helyreállítási költségei a legmagasabbak közé tartoznak.
A jogi és vállalati tanácsadók, valamint az adatvédelmi tisztviselők számára az olyan mesterséges intelligencia-rendszerek, amelyek emberi ellenőrzés vagy biztonsági átláthatóság nélkül dolgoznak fel rejtett dokumentumtartalmakat, egyre növekvő és jelentős kockázatot jelentenek.
OPSWAT CDR™ technológia ésSandbox Adaptive Sandbox mindkét iránybólSandbox ezt a hiányosságot. A Deep CDR™ technológia kiküszöböli azokat a szerkezeti feltételeket, amelyek lehetővé teszik az ilyen fenyegetések létrejöttét: ellenőrzi a fájlszerkezetet, eltávolítja az összes rejtett és ütköző dokumentumrészt, majd tiszta, ellenőrzött kimenetet generál, így biztosítva, hogy minden, a környezetbe belépő fájl pontosan azt a tartalmat hordozza, amelyet ellenőriztek.Sandbox Adaptive Sandbox hogy semmi ne maradjon ellenőrizetlenül: szerkezetérzékeny elemzést végez minden beágyazott dokumentumrétegen, mindegyiket függetlenül futtatja, és az eredményeket összehasonlítja az eredeti fájllal, így feltárja a fenyegetések viselkedési szándékát, amelyet egyetlen parser-trükk sem tud elrejteni. Ezek a technológiák együttesen biztosítják, hogy a felhasználók biztonságos tartalmat kapjanak, és hogy a támadók által a fájl számára tervezett funkciók teljes mértékben érthetőek legyenek.
További források
- AzOPSWAT portfóliójának megtekintése
- Adatlap letöltése: Deep CDR™ technológia és Adaptive Sandbox

