A fájlhamisítás továbbra is az egyik leghatékonyabb technika, amellyel a támadók megkerülik a hagyományos biztonsági ellenőrzéseket. Tavaly az OPSWAT bevezetett egy mesterséges intelligenciával feljavított fájltípus-érzékelő motort, hogy a korábbi eszközök által hagyott hiányosságokat pótolja. Idén a File Type Detection Model v3 modellel továbbfejlesztettük ezt a képességet, és azokra a fájltípusokra összpontosítottunk, ahol a pontosság a legfontosabb, és ahol a hagyományos logikai alapú rendszerek következetesen alulmaradnak.
OPSWAT File Type Detection Model v3 a többértelmű és strukturálatlan fájlok, különösen a szövegalapú formátumok, például szkriptek, konfigurációs fájlok és forráskódok megbízható osztályozásának speciális kihívására készült. Az általános osztályozókkal ellentétben ez a modell kifejezetten kiberbiztonsági felhasználási esetekre készült, ahol egy shell-szkript téves besorolása vagy a beágyazott makrókat tartalmazó dokumentum - például egy VBA-kódot tartalmazó Word-fájl - fel nem ismerése jelentős biztonsági kockázatot jelenthet.
Miért kritikus az igazi fájltípus-érzékelés
A legtöbb észlelőrendszer három közös megközelítésre támaszkodik:
- Fájl kiterjesztés: Ez a módszer ellenőrzi a fájl nevét, hogy a kiterjesztés alapján meghatározza a fájltípust, például .doc vagy .exe. Gyors és széles körben kompatibilis a különböző platformokon. Ugyanakkor könnyen manipulálható. Egy rosszindulatú fájl átnevezhető egy biztonságosnak tűnő kiterjesztéssel, és egyes rendszerek teljesen figyelmen kívül hagyják a kiterjesztéseket, így ez a megközelítés megbízhatatlan.
- Magic Bytes: Ezek olyan rögzített szekvenciák, amelyek számos strukturált fájl, például PDF vagy kép elején találhatók. Ez a módszer a tényleges fájltartalom vizsgálatával javítja a pontosságot a fájlkiterjesztésekkel szemben. Hátránya, hogy nem minden fájltípus rendelkezik jól meghatározott bájtmintákkal. A mágikus bájtok is hamisíthatók, és az eszközök közötti következetlen szabványok zavart okozhatnak.
- Karaktereloszlás-elemzés: Ez a módszer a fájl tényleges tartalmát elemzi, hogy következtetni tudjon annak típusára. Különösen hasznos a lazán strukturált szövegalapú formátumok, például szkriptek vagy konfigurációs fájlok azonosításához. Míg mélyebb betekintést nyújt, magasabb feldolgozási költségekkel jár, és szokatlan tartalom esetén hamis pozitív eredményeket produkálhat. Kevésbé hatékony az olyan bináris fájlok esetében is, amelyekből hiányoznak az olvasható karakterminták.
Ezek a módszerek jól működnek strukturált formátumok esetén, de megbízhatatlanná válnak, ha strukturálatlan vagy szöveges fájlokra alkalmazzák őket. Például egy minimális parancsokat tartalmazó shell-szkript nagyon hasonlíthat egy egyszerű szöveges fájlhoz. Sok ilyen fájlból hiányoznak az erős fejlécek vagy következetes jelölések, így a bájtminták vagy kiterjesztések alapján történő osztályozás nem elegendő. A támadók ezt a kétértelműséget kihasználva ártalmas szkripteket ártalmatlan dokumentumoknak vagy naplóknak álcáznak.
Az olyan hagyományos eszközöket, mint a TrID és a LibMagic, nem ilyen szintű árnyalatokra tervezték. Bár hatékonyak az általános fájlkategorizáláshoz, a széleskörűségre és a sebességre lettek optimalizálva, nem pedig a biztonsági korlátozások alatti speciális felismerésre.
Hogyan működik a File Type Detection Model v3
A File Type Detection Model v3 képzési folyamata két szakaszból áll. Az első szakaszban a tartományhoz igazodó előképzés történik maszkolt nyelvi modellezés (MLM) segítségével, amely lehetővé teszi a modell számára, hogy megtanulja a tartományspecifikus szintaxist és szerkezeti mintákat. A második szakaszban a modell finomhangolása egy felügyelt adathalmazon történik, amelyben minden egyes fájlhoz kifejezetten hozzá van rendelve a valódi fájltípus.
Az adatkészlet a szokásos fájlok és a fenyegető minták kurátori összeállítása, így biztosítva a valós világbeli pontosság és a biztonsági relevancia erős egyensúlyát. OPSWAT fenntartja az ellenőrzést a képzési adatok felett, lehetővé téve a folyamatos finomítást a biztonsági műveletek szempontjából legfontosabb formátumok tekintetében.
A mesterséges intelligencia összetevő alkalmazása precízen, nem pedig széles körben történik. A File Type Detection Model v3 olyan kétértelmű és strukturálatlan fájltípusokra összpontosít, amelyeket a hagyományos felismerési módszerek nem tudnak hatékonyan kezelni, mint például a szkriptek, naplók és lazán formázott szövegek, ahol a struktúra nem következetes vagy hiányzik. Az átlagos következtetési idő 50 milliszekundum alatt marad, így hatékony a valós idejű munkafolyamatok számára a biztonságos fájlfeltöltések, a végpontok kényszerítése és az automatizálási pipelinek terén.
Benchmark eredmények
Az OPSWAT fájltípus-felismerő motort a vezető fájltípus-felismerő eszközökkel összehasonlítva egy nagy és változatos adathalmazon hasonlítottuk össze. Az összehasonlítás során 248 000 fájl és körülbelül 100 fájltípus F1-pontszámát hasonlítottuk össze.
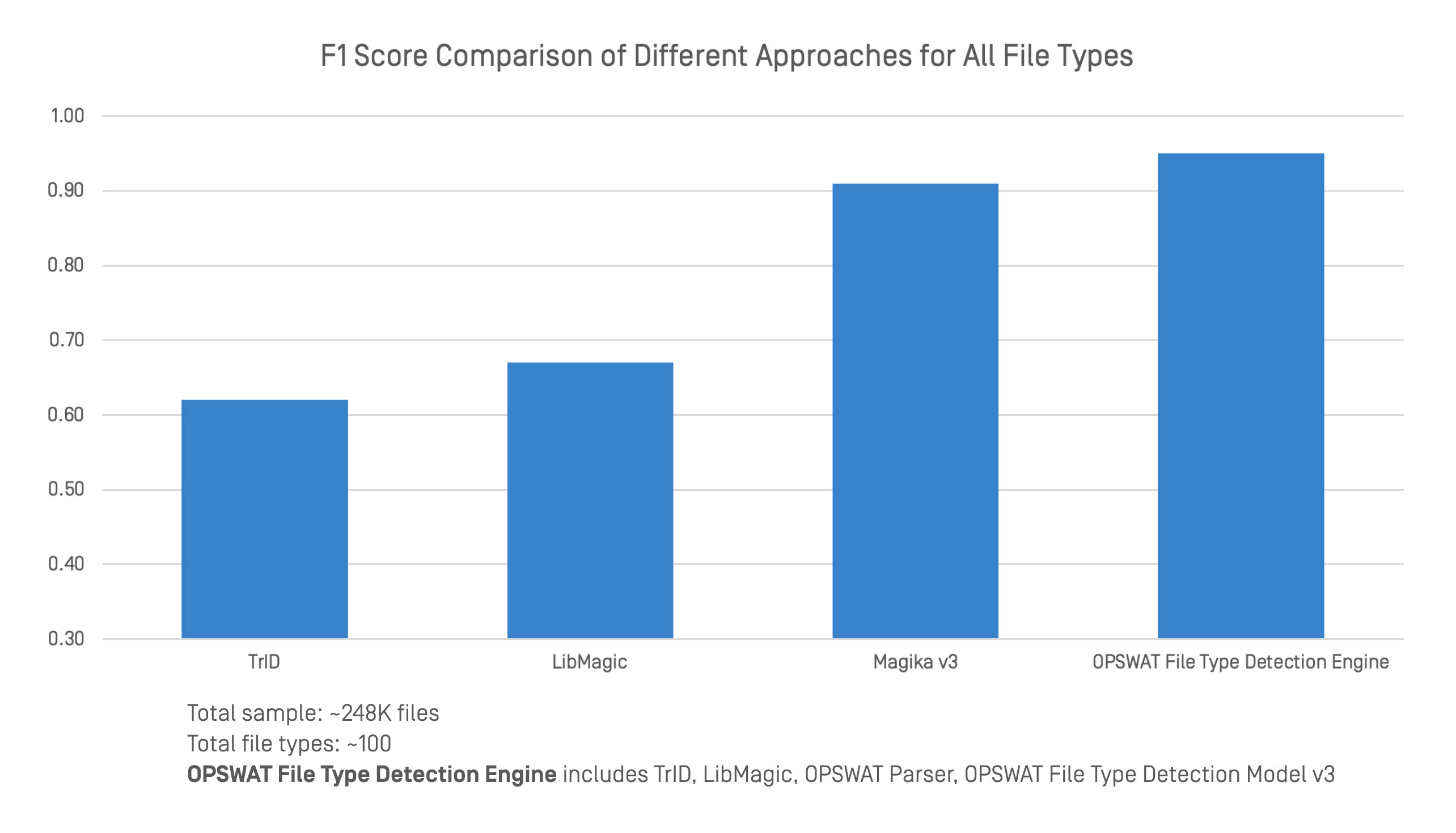
Az OPSWAT File Type Detection Engine többféle technikát integrál, beleértve a TrID-et, a LibMagic-ot és az OPSWATsaját technológiáit, például a fejlett elemzőket és a File Type Detection Model v3-t. Ez a kombinált megközelítés erősebb és megbízhatóbb osztályozást biztosít mind a strukturált, mind a strukturálatlan formátumokban.
A benchmark-tesztek során a motor nagyobb általános pontosságot ért el, mint bármelyik eszköz önmagában. Míg a TrID, a LibMagic és a Magika v3 bizonyos területeken jól teljesít, pontosságuk csökken, ha a fájlcímek hiányoznak, vagy a tartalom nem egyértelmű. A hagyományos felismerés és a mély tartalomelemzés rétegzésével az OPSWAT még akkor is egyenletes teljesítményt nyújt, ha a szerkezet gyenge vagy szándékosan félrevezető.
Szöveg és script fájlok
A szöveges és szkript-alapú formátumok gyakran érintettek a fájlokból származó fenyegetésekben és az oldalirányú mozgásban. Koncentrált tesztet végeztünk 169 000 fájlon az alábbi formátumokban, például .sh, .py, .ps1, és .conf.
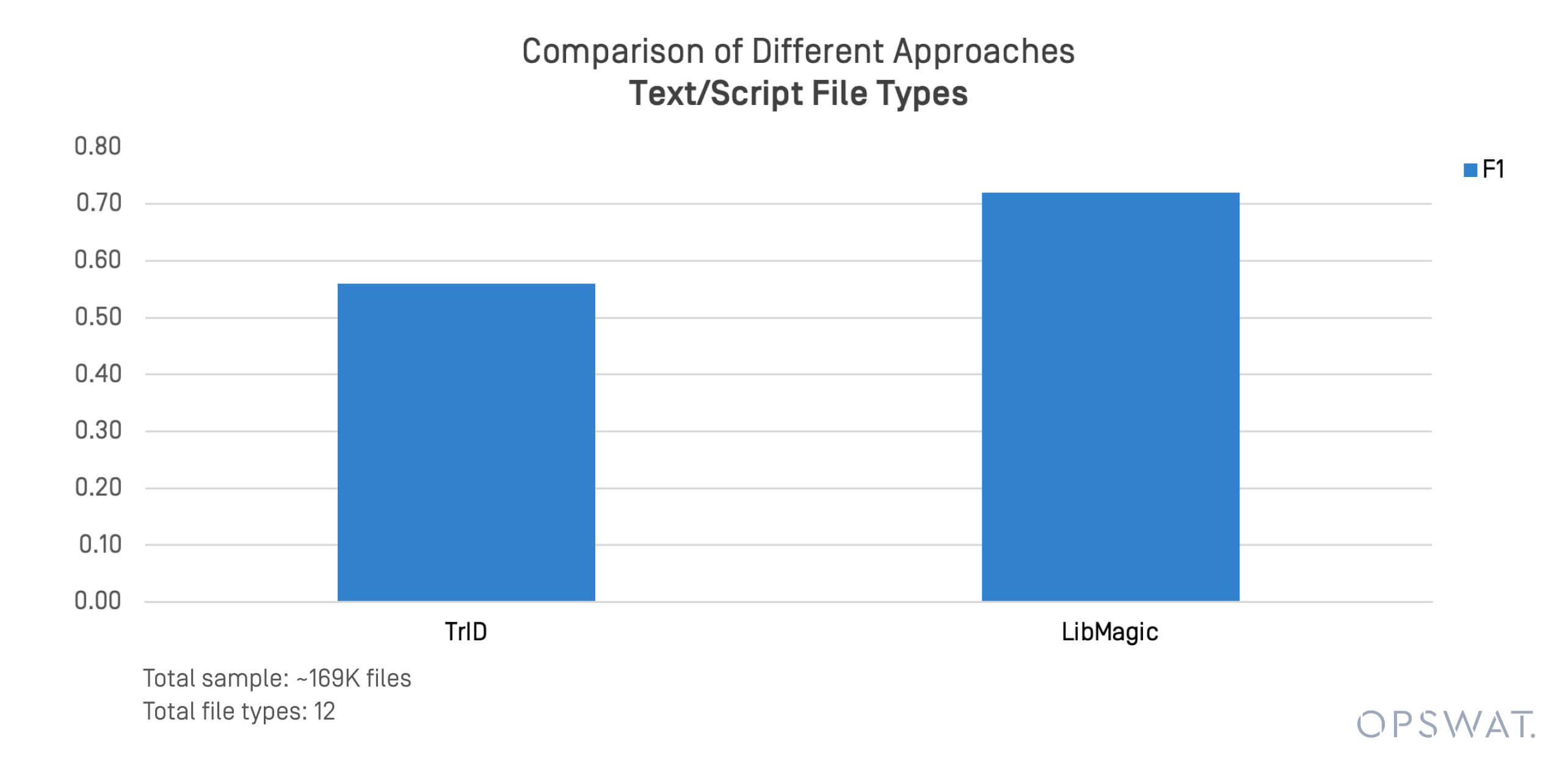
A TrID és a LibMagic korlátokat mutatott az ilyen strukturálatlan fájlok felismerésében. A teljesítményük gyorsan romlott, amikor a fájlok tartalma eltért az elvárt bájtmintáktól.
Fájltípus-felismerő modell v3 vs Magika v3
Az OPSWAT File Type Detection Model v3-t a Google nyílt forráskódú mesterséges intelligencia osztályozójával, a Magika v3-mal szemben 30 szöveges és szkript fájltípusra értékeltük, ugyanazt az 500 000 fájlból álló adathalmazt használva.
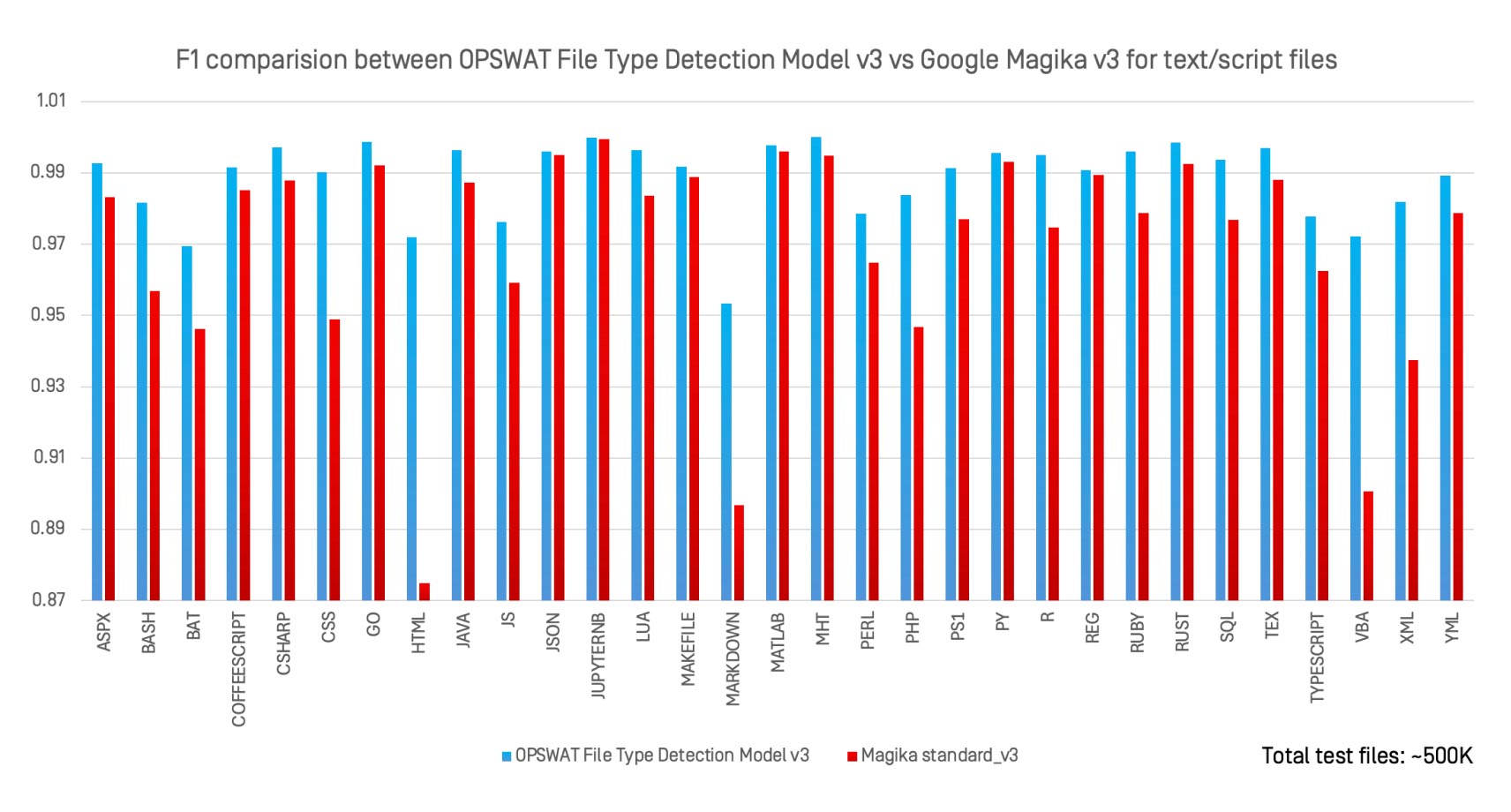
Főbb észrevételek:
- A File Type Detection Model v3 szinte minden formátumban megegyezett vagy felülmúlta a Magika teljesítményét.
- A legerősebb növekedést az olyan lazán meghatározott formátumok esetében tapasztalták, mint például
.bat, .perl, .html,és .xml. - A Magikával ellentétben, amelyet általános célú azonosításra terveztek, a File Type Detection Model v3 a nagy kockázatú formátumokra optimalizált, ahol a téves besorolásnak komoly biztonsági következményei vannak.
Legnépszerűbb felhasználási esetek
Secure fájlfeltöltések, letöltések és átvitelek
Megakadályozza, hogy álcázott vagy rosszindulatú fájlok kerüljenek be a környezetébe webes portálokon, e-mail mellékleteken vagy fájlátviteli rendszereken keresztül. A mesterséges intelligenciával kiegészített felismerés a kiterjesztéseken és a MIME fejléceken túlmutatva azonosítja az átnevezett fájlokban található szkripteket, makrókat vagy beágyazott futtatható fájlokat.
DevSecOps Pipelines
Állítsa meg a nem biztonságos artefaktumokat, mielőtt azok megfertőznék a szoftverépítési vagy telepítési környezetet. A valódi fájltípus tényleges tartalom alapján történő validálásával a MetaDefender Core biztosítja, hogy csak jóváhagyott formátumok haladjanak át a CI/CD csővezetékeken, csökkentve ezzel az ellátási láncot érő támadások kockázatát és fenntartva a biztonságos fejlesztési gyakorlatoknak való megfelelést.
Megfelelés végrehajtása
A pontos fájltípus-felismerés elengedhetetlen az olyan szabályozási előírásoknak való megfeleléshez, mint a HIPAA, a PCI DSS, a GDPR és a NIST 800-53, amelyek az adatintegritás és a rendszerbiztonság szigorú ellenőrzését írják elő. A hamisított vagy nem engedélyezett fájltípusok felismerése és blokkolása segít az érzékeny adatok kiszolgáltatottságát megakadályozó irányelvek érvényesítésében, az ellenőrzési készenlét fenntartásában és a költséges büntetések elkerülésében.
Végső gondolatok
Az olyan általános célú fájlosztályozók, mint a Magika, hasznosak a tartalom széles körű kategorizálására. A kiberbiztonságban azonban a pontosság többet számít, mint a lefedettség. Egyetlen rosszul besorolt szkript vagy tévesen címkézett makró jelentheti a különbséget az elszigetelés és a kompromittálás között.
Az OPSWAT fájltípus-érzékelő motor biztosítja ezt a pontosságot. A mesterséges intelligenciával feljavított fájltípus-elemzés és a bevált felismerési módszerek kombinálásával megbízható osztályozási réteget biztosít ott, ahol a hagyományos eszközök kudarcot vallanak, különösen a kétértelmű vagy strukturálatlan formátumok esetében. Nem arról van szó, hogy mindent lecserél, hanem arról, hogy a biztonsági stack kritikus gyenge pontjait valós idejű, kontextustudatos észleléssel erősíti meg.

